Here is Andrew Ng’s talk on this exact question which I recommend checking out. Although, it might be more relevant after you go over lesson 2 and 3 where we talk about other techniques like Regularization, Data augmentation, etc.
Here is my summary of the workflow:
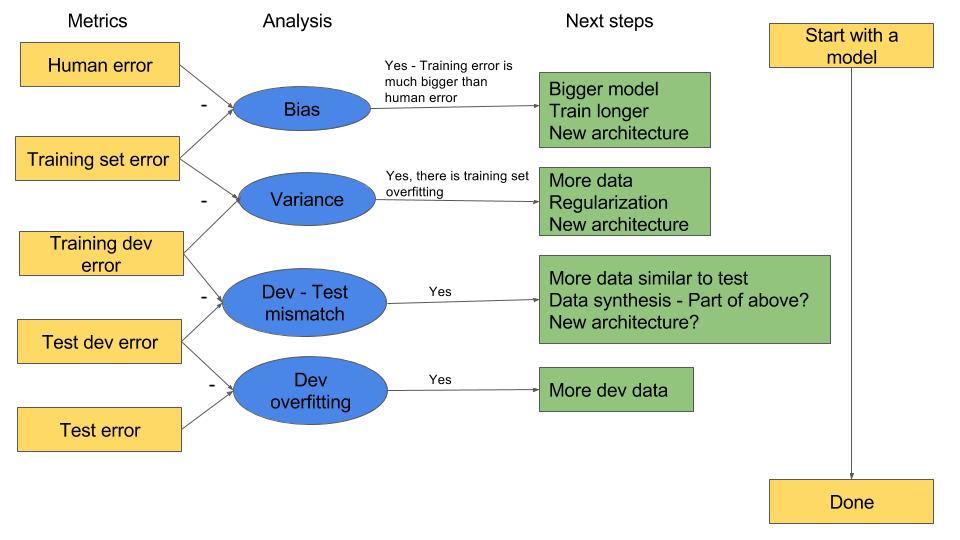
I put question marks for the ones which were mentioned in the talk but for which I am not sure of yet.
So for now (lesson 1), we are mostly only dealing with “Bias”, so we can try steps 1.Bigger model, 2. Train longer (more epochs)
Nope. They would not change.
I think the results would slightly change as the initial weights would be different (random) @jeremy may correct.
This is an interesting question, and I do not believe I have reached an optimum yet and tried until I think 20- 30 epochs. I am also interested in a general form of the question “How do we know running more epochs would not help? Because I did see results going up and down, so the gradient is not a sure sign.”