that is all the code minus imports and setting lowmem; including next. I got the types and other arg ideas from that link and similar at kaggle.
This python3 loadtrain.py fails:
import pandas as pd
import sys
lowmem = False
if len(sys.argv)>1 and sys.argv[1]=='-lowmem':
lowmem = True
types = {'id':'int32', 'data':'datetime64', 'store_nbr':'int16', 'item_nbr':'int32',
'unit_sales':'float32', 'onpromotion':'bool'}
sales = pd.read_csv('../data/train.csv',
dtype=types,
parse_dates=['date'],
infer_datetime_format=True # supposed to make it faster sometimes
,low_memory=lowmem # fails if false on Mac OS Sierra due to readline bug?
# ,nrows=500000 #Actually it's easier to do head from command-line
)
print(sales.info())
With low_memory=False it always dies a miserable death. Changing onpromotion to object doesn’t change anything.
The problem I had was that I misspelled date as data in types. When I spelled it correctly, I got a warning not to specify date formats and use parse_dates, which I was already doing. I still get a warning with this code:
import pandas as pd
import sys
lowmem = False
if len(sys.argv)>1 and sys.argv[1]=='-lowmem':
lowmem = True
types = {'id':'int32', 'store_nbr':'int16', 'item_nbr':'int32',
'unit_sales':'float32', 'onpromotion':'bool'}
sales = pd.read_csv('../data/train.csv',
dtype=types,
parse_dates=['date'],
infer_datetime_format=True,
low_memory=lowmem
)
print(sales.info())
Using the same args and these types from that webpage:
# From https://www.kaggle.com/heyt0ny/read-data-for-low-memory-usage
types = {
'id': 'int64',
'item_nbr': 'int32',
'store_nbr': 'int8',
'unit_sales': 'float32',
'onpromotion': bool,
}
I still get the warning.
In summary, that message appears no matter what I do. here’s another variation that doesn’t specify the argument
types = {'id':'int32', 'store_nbr':'int16', 'item_nbr':'int32',
'unit_sales':'float32', 'onpromotion':'bool'}
sales = pd.read_csv('../data/train.csv',
dtype=types,
parse_dates=['date'],
infer_datetime_format=True
)
I get
sys:1: DtypeWarning: Columns (5) have mixed types. Specify dtype option on import or set low_memory=False.
Whatever, it loads and I can move on to the next thing that dies for memory reasons. haha

 :
: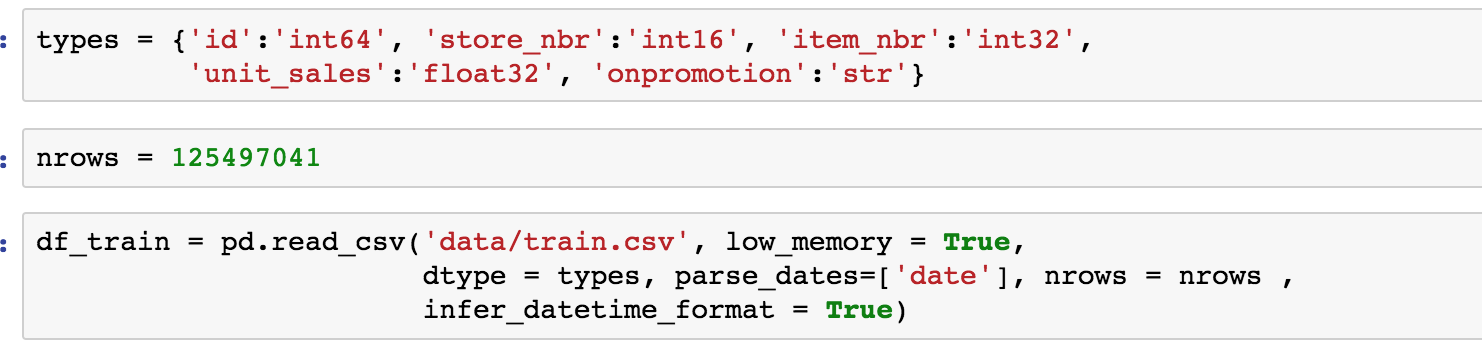


 That makes my life easier.
That makes my life easier.