Very helpful to get started with NLP in PyTorch( PS- only for beginners)
only for beginners)
2 Likes
It’s getting worse day by day. I think people are overfitting on LB. The same submission is used by many.
I am sure that at least up to 100-th position there is exact correlation between local CV and public leaderboard.
Hierarchical Attention Network in keras with Tensorflow backend https://www.kaggle.com/sermakarevich/hierarchical-attention-network
3 Likes
My latest vanilla pytorch code scored 0.9322 using a BiLSTM network.
Like others have mentioned, really need to pay attention at how test dataset are being processed.
In any case, rather happy with the results since training loss was around 0.066, so not much off from the final outcome
Using this as a reference: http://mlexplained.com/2018/02/08/a-comprehensive-tutorial-to-torchtext/
Prior to this was referring a lot to wgpubs code with little success. I think I managed to fix the randomized prediction but Kaggle score was just around 0.57. Might need more troubleshooting.
5 Likes
My Bidirectional GRU model with fastText embeddings scored 0.9847 on public leaderboard -
https://www.kaggle.com/atikur/simple-gru-with-fasttext-lb-0-9847
I trained few similar models with different pretrained word embeddings and got similar results.
I also tried more complex architectures, but didn’t get any improvements. Any suggestions would be greatly appreciated.
4 Likes
Focus more on preprocessing, try 10 fold validation and use pretrained embedding. With these 2 things you should be able to cross a single model score of .986+
2 Likes
Thanks for the hints. Were you able to cross 0.986+ with a single model?
Yes. A Simple Bi-Directional GRU with good preprocessing and fast text embeddings can give you easily .986+ . I am struggling on what to do next. Trying averaging , ensembling but not much success.
3 Likes
So preprocessing is the key. As I tried everything else and best score I got i 0.9852. Everything else (up to 0.9871) is blending based on train set OOF.
For me blending/ensembling gives 3-5 point boost in the 4th decimal . I am also using OOF.
Do you also use the public blend. When added with that , it gives me a light boost.
1 Like
I think the key here is to blend different models: blend RNN type networks + LR on TfIDF/Bayesian features + Tree Based predictions.
1 Like
What kind of pre-processing do you recommend? Any kernels we should be looking at.
I have a GRU (pytorch, fastai, fastext) that scores me a 0.976. I’m doing very minimal pre-processing/cleanup and I’m unsure about how to know what to cleanup and what preprocessing should be done.
Btw, my hyperparams:
max vocab size = 30,000
embedding size = 300
GRU hidden activations = 80
max seq. len = 100
Thanks - wg
@sermakarevich did you try using CapsNet yet? If tuned well I think it has good potential and at the very least may contribute well to a blend.
1 Like
No, I did not as I have no idea how it works. I am trying to figure out what guys are doing with preprocessing at the moment. Nothing worked for me so far so I assume it can give a boost up to 0.988 (difference between my current best model and @VishnuSubramanian best model).
I was able to improve the accuracy of my model when I started looking at the output of the tokenizer. Remember if the tokenizer does not do a good job then most of the words would end up as unknown as they will not be available in the pretrained embedding. So look for all the words which are being thrown away and try the different tokenizers of the top voted kernels and see which works better. You would be surprised a simple tokenizer would do a good job.
Spell checking can also give you a slight improvement.
@jamesrequa you are absolutely right . I tried CapsuleNet yesterday and it gave me a pretty good result of .9865+ without any fine tuning. But it takes a lot of time to train.
6 Likes
Hi all, this is baffling me. Any ideas why this error is being generated. I have read a couple of threads but still cant resolve the issue:
If I submit the original sample_submission file - no issues but once I use the same files with the predictions I get this error. Even tried the concatenation method in one of the Kaggle posts but still cant resolve.
Has anyone had this issue or any thoughts on how to resolve?
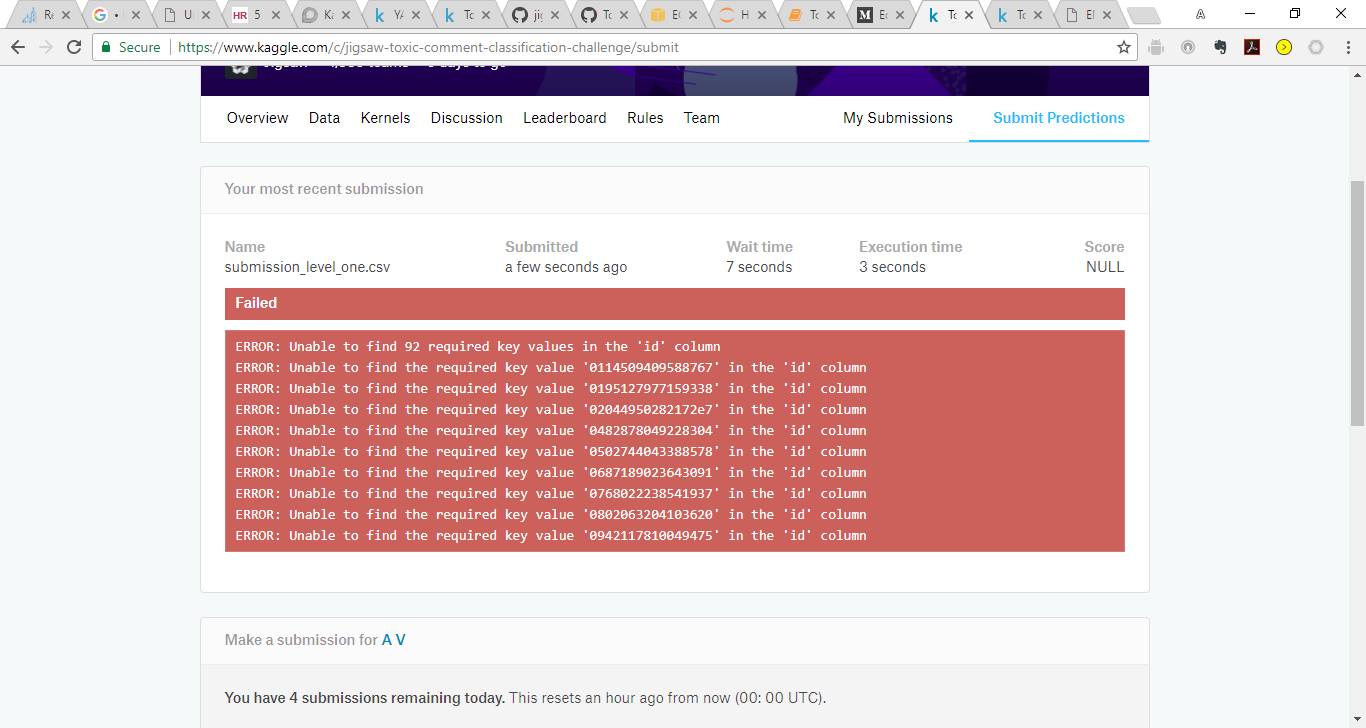
@amritv Make sure you set index=False when you save your submission file. I think this is probably the cause for it
@jamesrequa I am using index=False in the submission file, here is the code for the concatenation:
import os
import glob
import pandas
def concatenate(indir='Submissions/concat', outfile='Submissions/concat/concantenated.csv'):
os.chdir(indir)
dfileList=glob.glob('*.csv')
dfList=[]
colnames=['id','toxic','severe_toxic','obscene','threat','insult','identity_hate']
for filename in fileList:
print(filename)
df=pandas.read_csv(filename, header=None)
dfList.append(df)
concatDf=pandas.concat(dfList, axis=0)
concatDf.columns=colnames
concatDf.to_csv(outfile, index=None)I also tried the recommendation here https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge/discussion/48044 but this didnt work either.
This is mind boggling  and Im sure a simple fix
and Im sure a simple fix
@amritv That’s strange that Kaggle isn’t accepting it. You def shouldn’t need to do any concatenations of different csv files just to make the submission file.
I’m not sure if you tried this already, but here is some reference code for how you could generate a new submission file from scratch and then populate it directly with the prediction arrays for each class. This is assuming you are taking the predictions directly as they were generated from the model.
test_ids = pd.read_csv('./input/sample_submission.csv').id.values
columns = ['id','toxic', 'severe_toxic', 'obscene', 'threat', 'insult', 'identity_hate']
submission = pd.DataFrame(index=range(0,len(test_ids)), columns=columns)
submission[["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"]] = test_preds
submission.to_csv('submission.csv', index=False)
1 Like