Have a look at the messages from the top…
It will answer all…
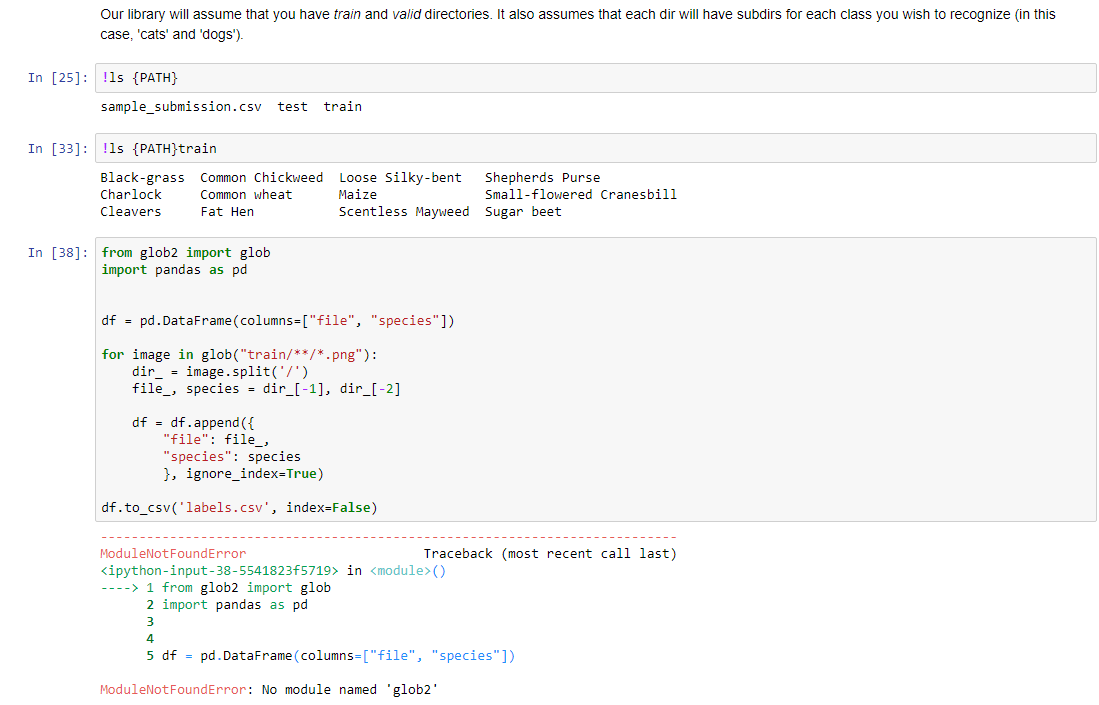
Regarding the CSV…
After removing the space inbetween,
At the time of submission we need to undo that …using
data.classes…
Have a look at the messages from the top…
It will answer all…
Regarding the CSV…
After removing the space inbetween,
At the time of submission we need to undo that …using
data.classes…
The steps are:
Download data from Kaggle under “data/seedlings/”
unzip train.zip under “data/seedlings/”
run the script and generate the labels.csv under “data/seedlings/” (then you can use this labels.csv to count and visualize the data)
Since we are going to use ImageClassifierData.from_csv, all the images need to sit under “train” folder and the sub-folders become redundant.
4. mv train/**/*.png to move files from species sub-folders to “train” folder
rm -r train/**/ to remove all species sub-foldersHope this help. All credit to @shubham24 to provide the codes.
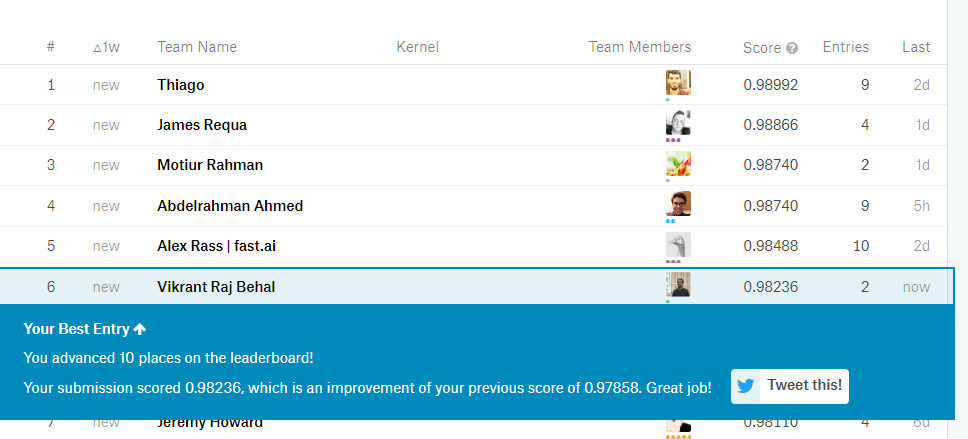
After five experiments (~3 hours), I submitted the best one.
Kudos to the fast.ai library.
I hope that put things in perspective for other people.
The thread to parse the data and to create the final CSV file was super useful.
Thanks to everyone that shared their insights.
Maybe a late reply and you probably don’t need it anymore but still 
def f1(preds, targs):
preds = np.argmax(preds, 1)
targs = np.argmax(targs, 1)
return sklearn.metrics.f1_score(targs, preds, average='micro')
learn = ConvLearner.pretrained(f_model, data=data, ps=0.5,xtra_fc=[], metrics=[f1])
My targets are one-hot encoded for example [0, 0, 1, 0, 0, 0, 0, 0, 0, 0] -> class 3
This worked for me 
Thank you.
https://drive.google.com/file/d/1WCQtBTWD2cpNZ76h1YgYae4SXqjai3lt/view?usp=sharing
Use this csv file
its has been edited…
conda install glob2
Thanks
thanks aditya
Okay. Looks like I’m struggling with this competition but seems like it’s giving me an opportunity to play with many parameters.
With bs of 64 or 32 I wasn’t getting a curve which flattens or loss starts to increase so I tried bs of 16. This is how my lr curve is. This suggests me to use 1 as lr which eventually giving no better than .6 f1 score.
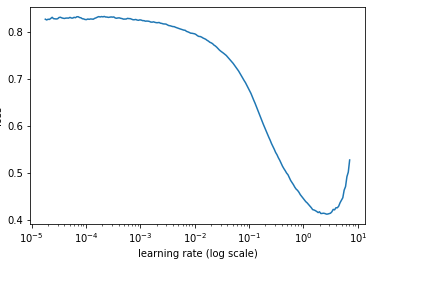
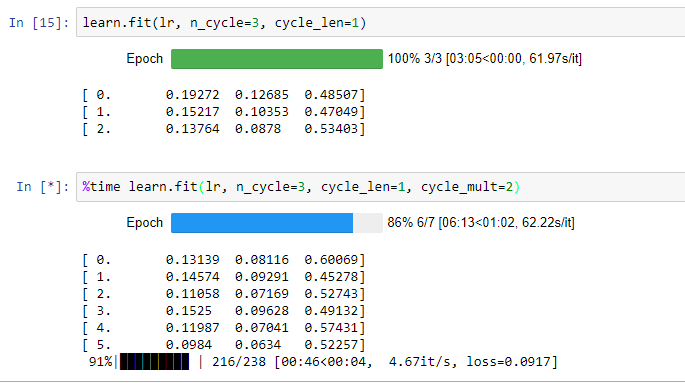
Any guidance?
I am getting the same error. I have deleted the sub-folders in train folder but i checked again to make sure. How did you fix this?
I would say you have some issues with data/labels/filenames/anything_not_related_to_training. You have an incredibly low loss (lower than even @jamesrequa declared in this thread) and very low accuracy with high variance. In three epochs (one of which after unfreeze) you should get 0.9 + accuracy with 4-5 times higher loss.
Check whether you are passing suffix or not…
In my case I was…
Oh yes! I was passing suffix. My bad. Thanks!
I redid everything and ignored f1 metrics for now and things are looking promising.
Question: reduced batch size to 32 for this problem (even though GPU could accommodate) so that each epoch (gradient) gets more time to learn? Or right way to think is because we had less number of images?
10 places improvement happened because of this equation.
lrs=np.array([lr/18,lr/6,lr/2]) than original lrs=np.array([lr/9,lr/3,lr])
Now it’s solved?
Yes!
Jeremy would be proud.
Disregard this, didn’t see that you’ve fixed it already