Do you guys switch to differential learning rates only after your normal learn.fit stops reducing validation loss or is it one of those things you need to get a feel for?
Anytime I’m finetuning lower layers with unfreeze then I always use differential learning rates. If I’m just training top layers then I just stick with one learning rate.
4 Likes
I might have phrased that poorly - it was my understanding that i should always start by training top layer, then finetuning lower layers with differential learning rates, and i was wondering when do i decide that it’s time to train lower layers too. Is that not correct, are you finetuning all layers from the start?
1 Like
The truth is it really depends on the dataset/problem. But my own personal general rule of thumb is usually to initially train top layers followed by finetuning lower layers. For the top layers, I don’t typically do more than 3 cycles or so, just enough to get the loss rates to a reasonable starting point before finetuning lower layers.
11 Likes
That’s what i wanted to know. Thank you James!
Woah. That’s pretty remarkable.  Can you share any general insights on fine-tuning while avoiding overfitting ?
Can you share any general insights on fine-tuning while avoiding overfitting ?
tbh everything you need to know is in the lesson notebooks that we have covered so far in this course  The more practice you get training different models and observing how the loss rates change the better intuition you will have. For finetuning, if you get the learning rates right and take advantage of cycle_len and cycle_mult you should be able to avoid overfitting. It can also be quite helpful to save your weights at the end of each cycle with cycle_save_name so you can basically just cherry pick the best loss rate that occurred before you started overfitting. This can often take quite a bit of trial and error to get right, so don’t expect everything to just “work out” on the first try.
The more practice you get training different models and observing how the loss rates change the better intuition you will have. For finetuning, if you get the learning rates right and take advantage of cycle_len and cycle_mult you should be able to avoid overfitting. It can also be quite helpful to save your weights at the end of each cycle with cycle_save_name so you can basically just cherry pick the best loss rate that occurred before you started overfitting. This can often take quite a bit of trial and error to get right, so don’t expect everything to just “work out” on the first try.
9 Likes
Thanks James. I’ve yet to start saving weight at the end of each cycle. After tweaking around learning rates(slightly), cycle_len and cycle_multi, I still find that sudden overfitting happens now and then, ruining everything that comes afterwards. I’ll try saving/using the weights at end of the cycles as well. 
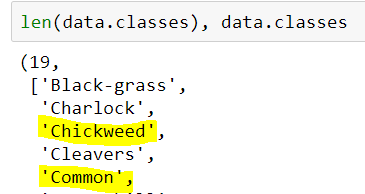
It works in the data frame (12 species). When I pass the same csv file into ImageClassifierData.from_csv, I got 19 species. The problem caused by white space. How to fix it?

See earlier in this thread
1 Like
14 Likes
Kaggle provided the training dataset in folders. Why do you prefer from_csv to from_path?
1 Like

It seems Jeremy should also make one more prediction on LB…
2 Likes
pred_classes = [data.classes[i].replace("", "_") for i in preds]
Something Like this…
Or replace them in csv directly…
Can’t upload the .csv here…
1 Like
I guess there are plenty of ways to do this. Here’s another way to do it in the dataframe:
label_df.species = label_df.species.apply(lambda x: re.sub(' ', '_', x))
2 Likes
I use the script you mentioned ti create labels.csv and also do the following steps to remove the folders from the train folder. But after that my data frame is empty and also the csv file dosen’t show up in my PATH.
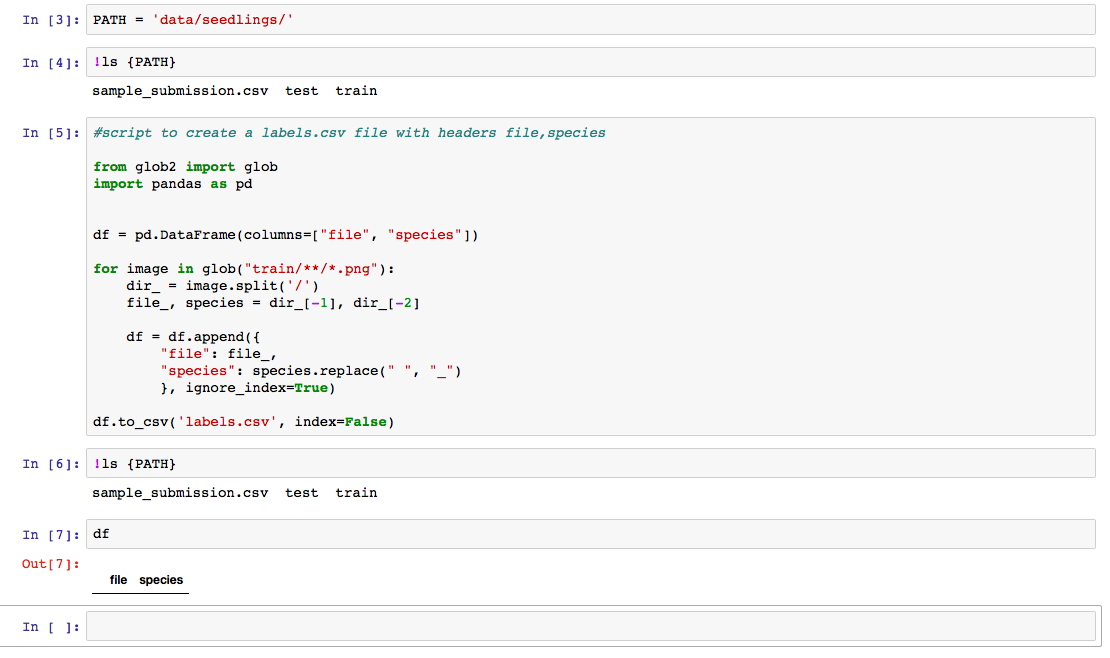
What am i doing wrong
Your df.to_csv call is not storing the csv file in PATH but in the current working directory (where your notebook is). To save it to PATH, you need to add that in the call to to_csv.
It’s actually saving in fastai directory as per your method…
Simply Do a mv
I did a mv but the data frame still shows empty.
Just checking if i got it right : The downloaded data is in folders for each species. So should i be creating the “labels.csv” first and then move the images to parent train folder and delete the empty species folders? OR
First move images to parent train folder, create csv and then delete the empty species folders.
I try both ways and it is still the same.