I am sorry @alessa, what graphs are you referring to? - updt: Found.
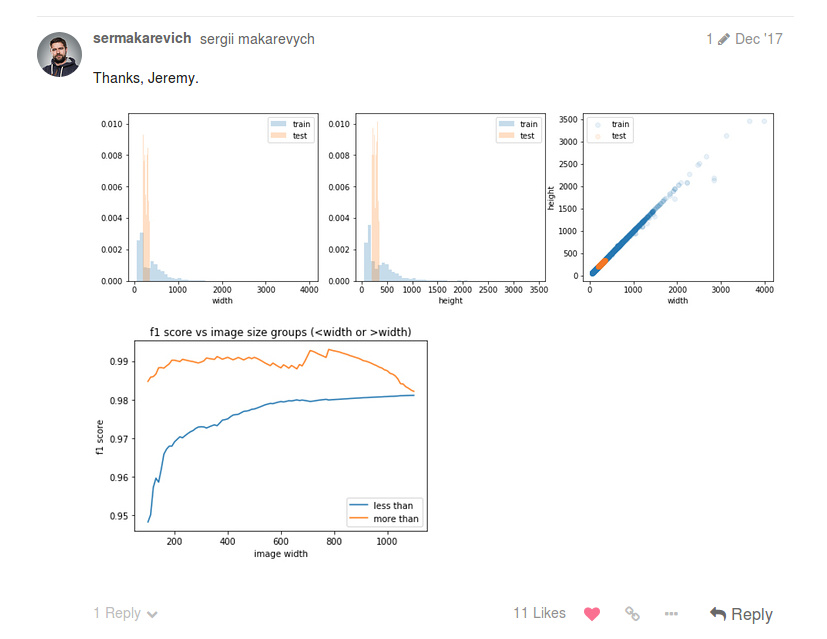
First chart is just plt.hist of images width, second one - of image height, third one - plt.scatter of width/height. To build the forth I use OOF predictions of a train set and calculate the score by selecting only images that satisfy criteria: < than some size or > than some size.
I was able to do well with success down to 1. emsembling what I found to be the strongest performing architectures (resnet50 and nasnet), 2. spending time fine tuning hyper parameters and image sizes, 3. running k-fold cross validations, and more than once. I think these are good steps for any serious attempt at any leaderboard climbing on any similar competition, and was a good starter learning experience. The competition has closed, but remains a good one to practise these skills.
Here is the notebook snipet for my first attempt at this competition. I think its a good place to start.
Just vanilla fastai tips. No cross-validation, ensemble, segmentation of any sorts. I have just kept an eye on the losses, nothing more. I haven’t added any documentation, cause, I followed jermey’s tips nothing more. If you need explanation. Just ping me, I’ll add up.
0.988 accuracy. Around 0.97 in public leaderboard.
There were two classes in this problem which had some kind of correlation with each other. Most of the errors were due to this. If I want my model to concentrate more on classifying these two classes. How should I approach the problem?
some intuition that I had …
So, can I train a model specifically for these two classes and ensemble it with my main predictions (updating only these two classes). Or, do you recommend any other approach?
I did not to that, I just blended multiple models, which predicted all classes at once. But I have no idea if your approach will work, just give it a try.
@SHAR1 Try oversampling (duplicated all images) Black-grass in your training set. It has half the number of samples of Loose Silky-bent which is the other class it gets confused with.
This may be the wrong approach but I got 0.98740 with vanilla Resnet50, top down aug and incorporation of the validations set at the end.
My first Kaggle competition. Got 0.97858 with Resnet50. No crossvalidation.
I haven’t done nothing special, but it’s nice to get good results with so little experience. It gives me motivation to move forward and it was fun )
In this competition, my first Kaggle, I obtain 0.98614 (in the public leaderborad, for what that means) !! Thanks to the Jeremy tips and the fastai software.
Used only Resnet50, resnext gave me memory error and I was not able to load nasnet.
I wanted to use all the examples but did not find any other solution than reducing val_pct. I still do not know how to train on all the examples.
I performed about 5-6 trainings, then I checked the wrong classified patterns. Most of the time the errors came from misclassification between class 0 and 6 (sorry now I dont remember the class names), but one model was different, it worked better over the 0-6 and worst over another couple. So, finally, I created an ensemble of just two classifier.
I really would like to know how you debug the code. I’m working with spyder and this is really a pain.
It seems impossible to put a breakpoint, check some values and continue.
Does it exist any IDE that allows to manage decently the debugging ?
change code :
from glob2 import glob --> from glob import glob
for image in glob(“train//*.png"): —> for image in glob("{}/train//*.png”.format(PATH)):
did you solve your problem ? I’m trying as well to use f1 metric in m.fit(lr, 3, metrics=[f1]) but it gives the following error. Any advice ?
RuntimeError: invalid argument 3: sizes do not match at c:\anaconda2\conda-bld\pytorch_1519501749874\work\torch\lib\thc\generated…/THCTensorMathCompareT.cuh:65
Did anybody triy to predict single images downloaded from the internet?
My model has ~96.5% accuracy. I tried to load 10 pictures with somehow similar to the pictures of the training set from google images (tried to pick those that had single leaf, soil background …etc). But the model predicted all wrong!
I suspected that there is something wrong with my code. Tried several pictures from the validation set and all predicted correct except for the few that I know it was confusing for the model and that’s why it has 96% accuracy.
It is weird that no single picture from the internet predicted well…
Does that mean the model is overfit on the kaggle dataset because it does not have varieties of backgrounds , lighting changes …etc.?
I followed the template of dog breeds of Jeremy. And the single file prediciton like Jeremy’s code:
Should we do normalization for the pictures before making prediction?
I thought this is already done in part of fastai so I did not make any changes to the pictures.
{kind=link}