@PranY really appreciate your insights, I re-ran my notebook and primarily got the same results and will let you know about your second suggestion…
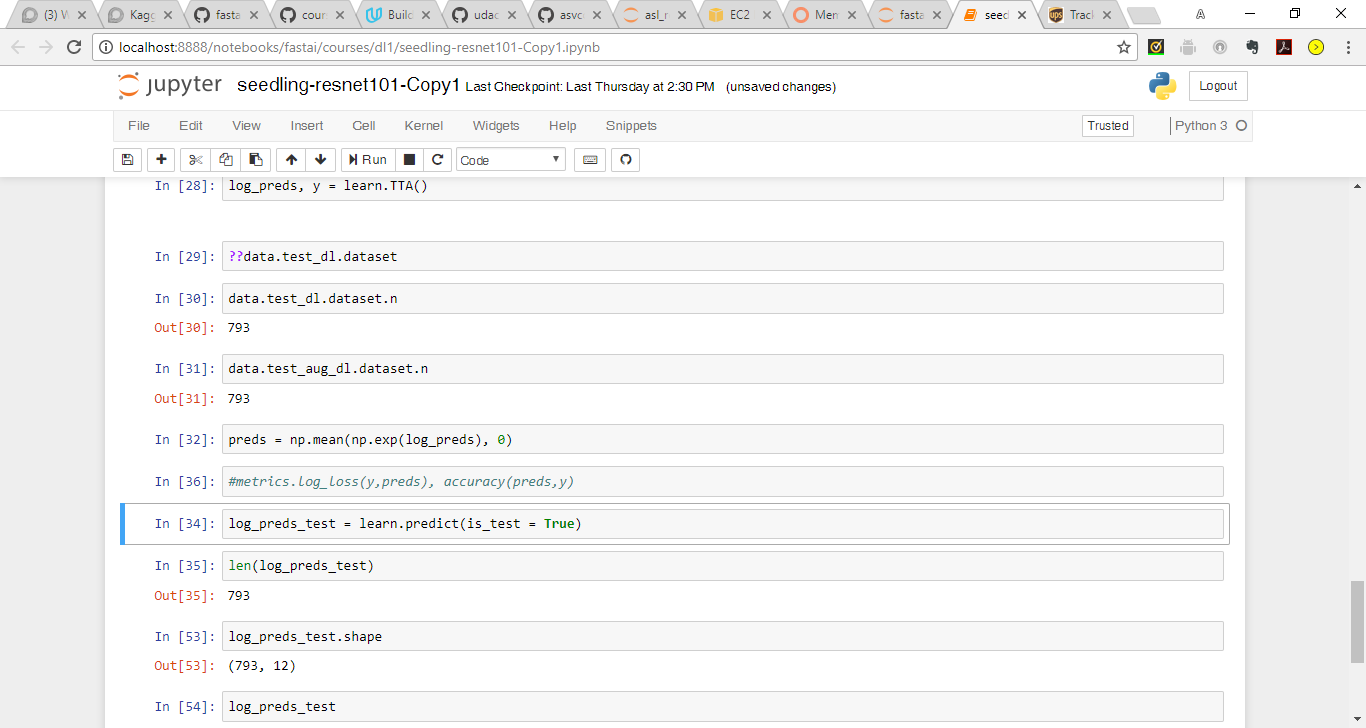
@amritv I can see your data.test_dl.dataset.n is itself 793. I strongly believe the learn or TTA step is not related to this problem. The source for data is the “ImageClassifierData.from_csv” method which revolves around your train/test folders, label.csv and val indexes. Since your word count for train/test is right, my best guess is that the part where you are creating val indexes using n, relies upon an assumption that your labels does include the titles ‘id’ and ‘species’. If thats not the case then the source method will inherently pull 1 less record. Please print “data.trn_dl.dataset.n + data.val_dl.dataset.n” and that should match with your word count for train folder which is 4750. If it doesn’t I think we found the root cause.
Please revert back if this helps.
3 Likes
@PranY Firstly, your insights are really helping me dig deeper into the fastai code and get a more better understanding of what is happening under the hood. I ran data.trn_dl.dataset.n + data.val_dl.dataset.n and the total count is the same as the train folder 4750.
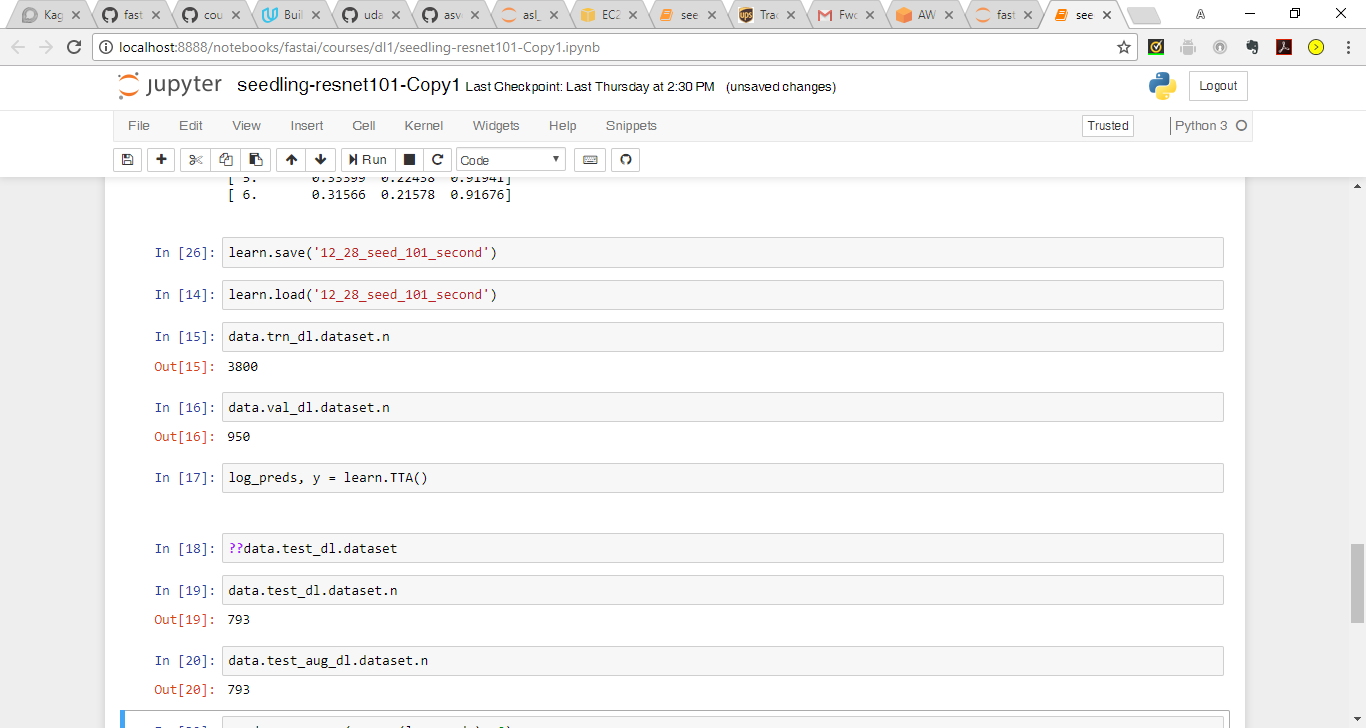
I wanted to get a better understanding of what is happening here:
labels_csv = f'{path}labels.csv'
n = len(list(open(labels_csv)))-1
val_idxs = get_cv_idxs(n)n= 4750
labels_csv = 24 (where does this number come from - 12 classes and 2 columns?)
len of val_idxs is 950 (where does this number come from?)
Thanks,
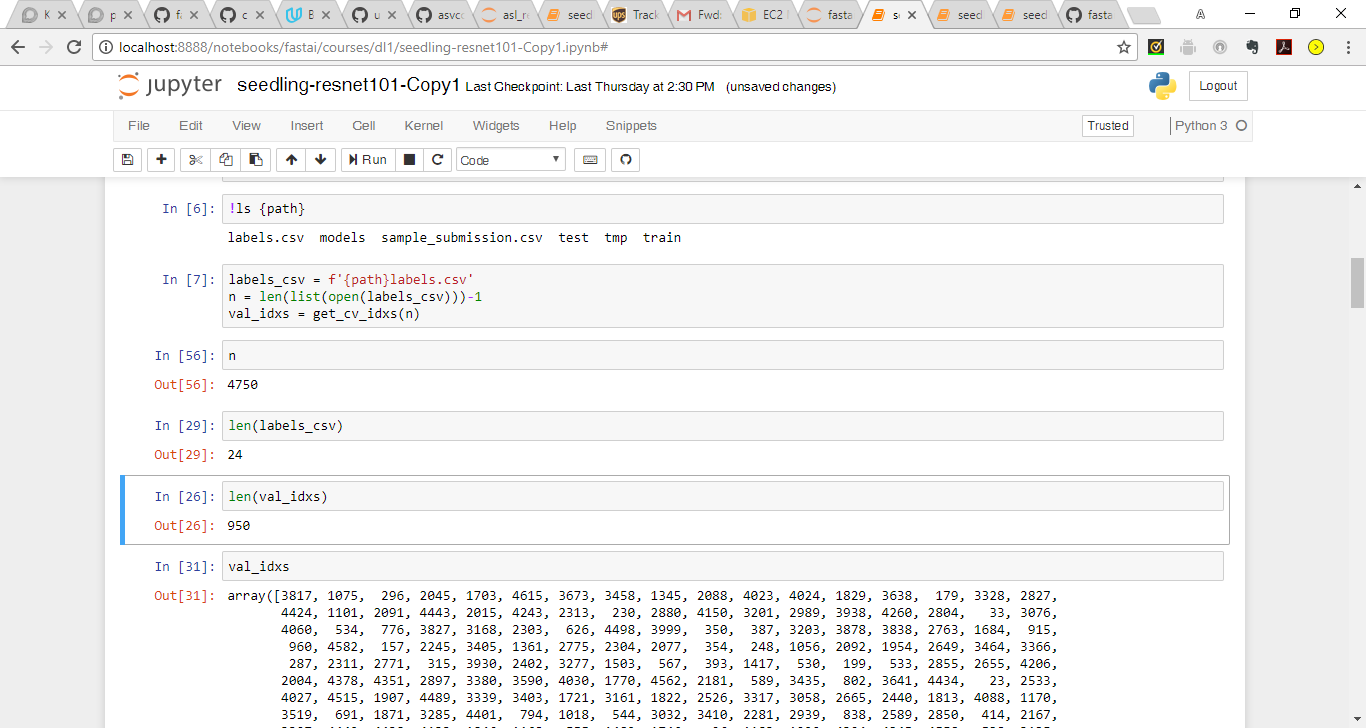
Here n is the length of (labels_csv-1) i.e minus the header. val_idxs is 20% of n.
I am facing the same issue while doing TTA and am not able to create a submission file. Were you able to fix the error, if so how? I checked ‘data.trn_dl.dataset.n + data.val_dl.dataset.n’ according to @PranY and it is the same as train folder i.e 4750.
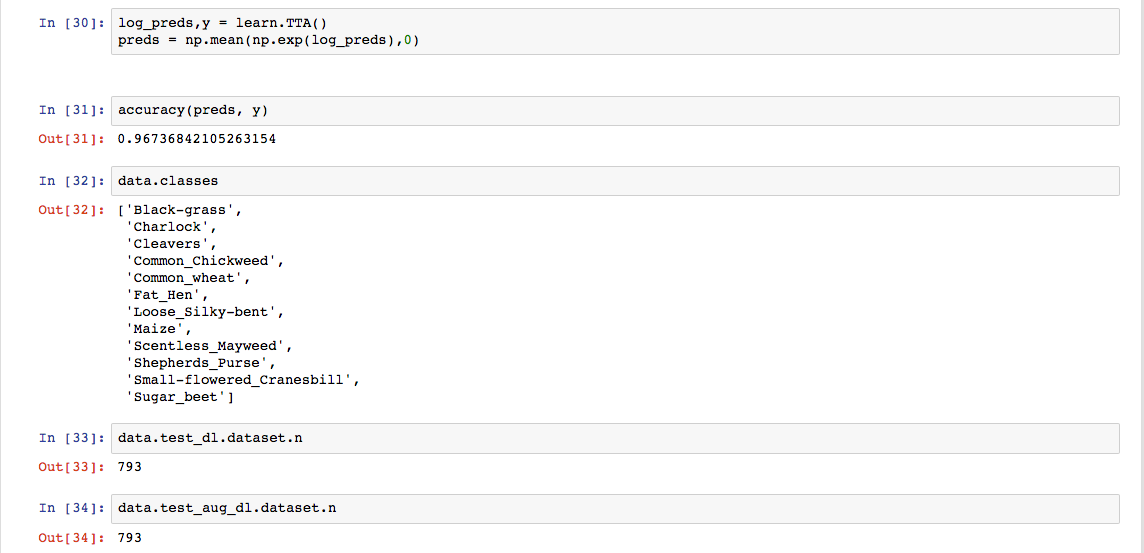
Unfortunately not but was able to generate a submission. I also started from scratch and reviewed learner and dataset.py, reviewed videos (no solution but learnt alot about the fastai library  )
)
Running this code right at the beginning
data = ImageClassifierData.from_csv(path, 'train', labels_csv, test_name='test', val_idxs=val_idxs, bs=bs, tfms=tfms, skip_header=True, continuous=False)
learn = ConvLearner.pretrained(arch, data, precompute=True)creates the tmp file which as 793 entries instead of 794 hence no need to train the model fully all the way to realize there is a difference in the sizes. The tmp files dont correspond to anything I can reference back to the 794 in the test folder. The meta file provides shape, cbytes and nbytes. Is there any way to know what the data corresponds to in the tmp file?
Seems like you ran into the same problem as I did. I created an issue and pull request to solve the problem. https://github.com/fastai/fastai/issues/77
2 Likes
Thanks for the PR @FabianHertwig! I’ve merged it, but didn’t have time to test it, so if folks here could check it works for both this comp and the existing lessons, that would be much appreciated…
3 Likes
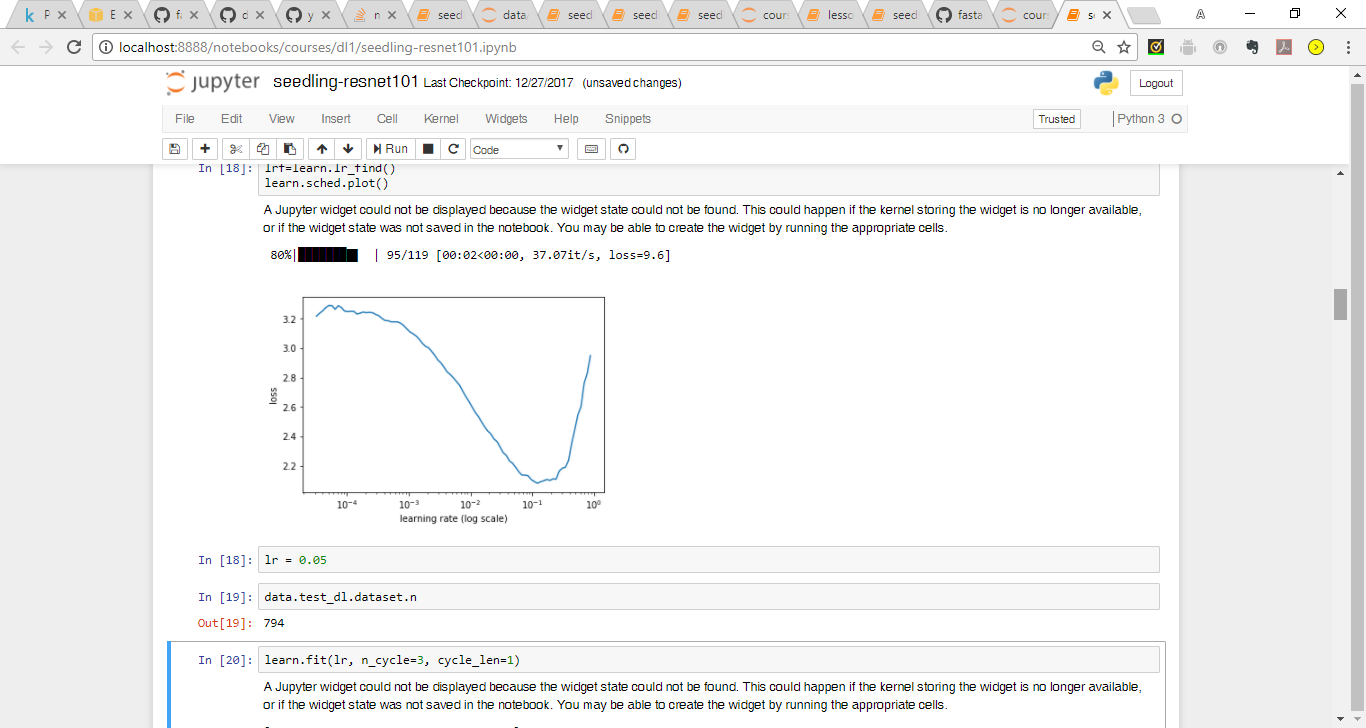
Ran into this problem for the dog breed identification and the pull request fixed everything.
Had a great time with this competition. I ended up just beating Jeremy after thinking a little more about how to fine-tuned the network before unfreezing the network and enabling differential learning rates. My score ultimately ends up tying for 22nd on the public leaderboard!
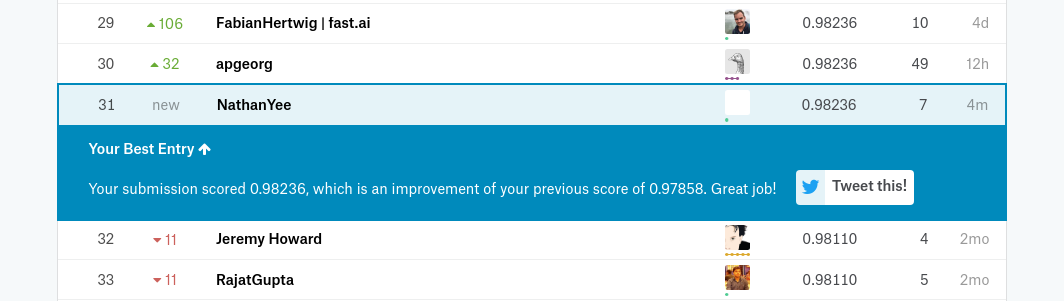
Good luck to everyone!
3 Likes
Congratulations
1 Like
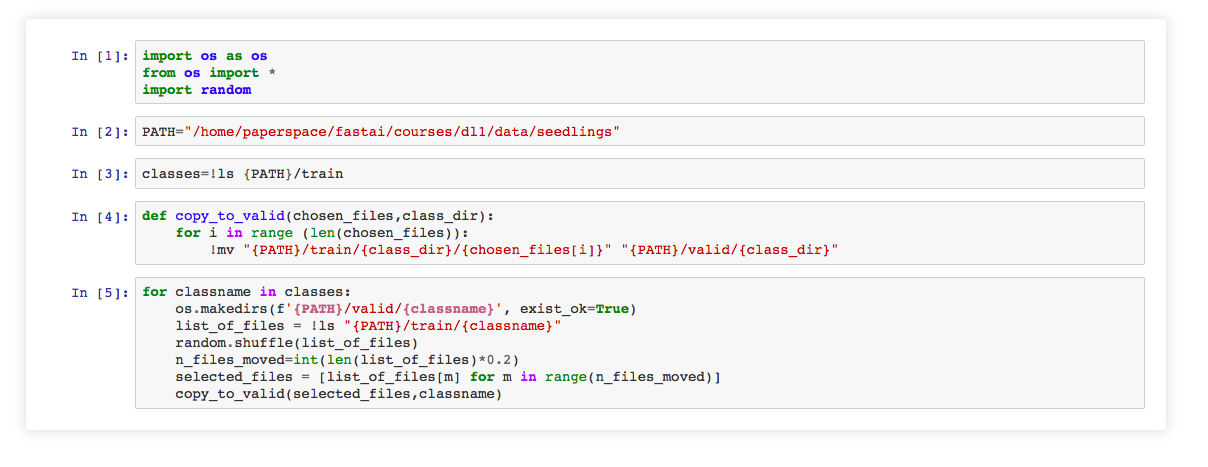
I created a small python to create validation directories and move 20% of the files to validation set. Feel free to modify the PATH variable and the % as you like.
3 Likes
Attach the source code here?
Did you find a solution to adding it to learn.fit()
Hi @shubham24 ,
Apologies if this question is slightly off topic, but for:
glob(“train/**/*.png”)
in the script you wrote, am I able to use a token like {PATH} with glob in case I dont want to run the script in the same directory?
I tried:
for image in glob("{PATH}train/**/*.png"):
and
for image in glob(“f’{PATH}train/**/*.png”):
but both did not work.
In other words, how can I change the script you wrote to allow me to run it in any directory? This is so that I can just leave it in a single directory and be able to use it for different kaggle datasets.
Ian
I think you’re using the wrong syntax.
Try:
for image in glob(f'{PATH}train/**/*.png'):
You may want to read this post: https://cito.github.io/blog/f-strings/
Thank you for the fix and pointing me in the right direction to learn more.
Appreciate it!
Hi! I am getting an error whenever i run a function to calculate lean value.
learn = ConvLearner.pretrained(arch, data)
lrf=learn.lr_find()
learn.sched.plot()
Please help in resolving this error. Error log is below:
TypeError Traceback (most recent call last)
in ()
----> 1 lrf=learn.lr_find()
2 learn.sched.plot()
~/fastai/fastai/learner.py in lr_find(self, start_lr, end_lr, wds, linear)
250 layer_opt = self.get_layer_opt(start_lr, wds)
251 self.sched = LR_Finder(layer_opt, len(self.data.trn_dl), end_lr, linear=linear)
–> 252 self.fit_gen(self.model, self.data, layer_opt, 1)
253 self.load(‘tmp’)
254
~/fastai/fastai/learner.py in fit_gen(self, model, data, layer_opt, n_cycle, cycle_len, cycle_mult, cycle_save_name, use_clr, metrics, callbacks, use_wd_sched, norm_wds, wds_sched_mult, **kwargs)
154 n_epoch = sum_geom(cycle_len if cycle_len else 1, cycle_mult, n_cycle)
155 return fit(model, data, n_epoch, layer_opt.opt, self.crit,
–> 156 metrics=metrics, callbacks=callbacks, reg_fn=self.reg_fn, clip=self.clip, **kwargs)
157
158 def get_layer_groups(self): return self.models.get_layer_groups()
~/fastai/fastai/model.py in fit(model, data, epochs, opt, crit, metrics, callbacks, **kwargs)
104 i += 1
105
–> 106 vals = validate(stepper, data.val_dl, metrics)
107 if epoch == 0: print(layout.format(*names))
108 print_stats(epoch, [debias_loss] + vals)
~/fastai/fastai/model.py in validate(stepper, dl, metrics)
126 preds,l = stepper.evaluate(VV(x), VV(y))
127 loss.append(to_np(l))
–> 128 res.append([f(preds.data,y) for f in metrics])
129 return [np.mean(loss)] + list(np.mean(np.stack(res),0))
130
~/fastai/fastai/model.py in (.0)
126 preds,l = stepper.evaluate(VV(x), VV(y))
127 loss.append(to_np(l))
–> 128 res.append([f(preds.data,y) for f in metrics])
129 return [np.mean(loss)] + list(np.mean(np.stack(res),0))
130
~/fastai/fastai/metrics.py in (preds, targs)
11
12 def accuracy_thresh(thresh):
—> 13 return lambda preds,targs: accuracy_multi(preds, targs, thresh)
14
15 def accuracy_multi(preds, targs, thresh):
~/fastai/fastai/metrics.py in accuracy_multi(preds, targs, thresh)
14
15 def accuracy_multi(preds, targs, thresh):
—> 16 return ((preds>thresh)==targs).float().mean()
17
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/tensor.py in eq(self, other)
346
347 def eq(self, other):
–> 348 return self.eq(other)
349
350 def ne(self, other):
TypeError: eq received an invalid combination of arguments - got (torch.cuda.FloatTensor), but expected one of:
- (int value)
didn’t match because some of the arguments have invalid types: (torch.cuda.FloatTensor) - (torch.cuda.ByteTensor other)
didn’t match because some of the arguments have invalid types: (torch.cuda.FloatTensor)