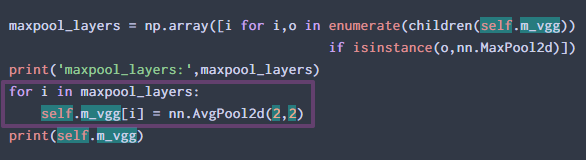
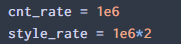
I might be wrong, but this seems to be making a significant difference? If so, maybe this could be added to the lesson 13 notebook, maybe even as a sidenote at the bottom if not inline?
Something that might work well with the images you use (high frequency, complex patterns) that I explored is to dramatically increase the ratio between style loss and content loss. I found a really interesting result when I went up to 1000:1. What happens is that the network takes much longer to train and converge, but I thought the results were much better looking.
I posted it on the fora in the 2017 course. Here’s a link to the results and a corresponding explanation.
It’s something I meant to explore more deeply, but haven’t had the chance.
Have you tried training for longer? If you look at the thread, within the first 10 epochs you don’t really see the content, it only really starts to appear more slowly after that point. It takes ~75 epochs to get a good result. That’s way higher than the more balanced, which looks somewhat good even after a single epoch and generally converges in 5-10 epochs.
I usually train at least 600 epochs, the loss will lower than 4000, depend on the style image, sometimes the loss was high, but looks good.
and for some style images I will train for 2000 epoch.