Hi @jayashree
Do you actually have a test directory so that the following returns False?
(learn.data.test_dl == None)
Hi @jayashree
Do you actually have a test directory so that the following returns False?
(learn.data.test_dl == None)
Yes I have a test folder inside data folder.
OK, is it called test, or test1? I note that the default test directory on lesson1 is test1.
I also note that the jupyter notebook for lesson 1 does not add the test data. Therefore you added the test data to your model, doing something like this?
data = ImageClassifierData.from_paths(PATH, bs=bs, tfms=tfms, test_name='test1')
And if you issue this command, you don’t get an error?
str(data.trn_ds), str(data.val_ds), str(data.test_ds)
Getting something like this?
('<fastai.dataset.FilesIndexArrayDataset object at 0x0000023C06ABCB70>',
'<fastai.dataset.FilesIndexArrayDataset object at 0x0000023C06ABCDA0>',
'<fastai.dataset.FilesIndexArrayDataset object at 0x0000023C06ABCC50>')
Thanks @Chris_Palmer
I was getting the same error and adding test_name=‘test_directory_name’ solved the problem for me
 The use of a test set confused me at first, as I was acquainted with the idea of train and test sets, where the test set is used to validate the training. But in the fastai library, the test set is what is used to submit to kaggle competitions - hence there are no labels - the result is unseen until you get feedback from submitting to kaggle on the test set.
The use of a test set confused me at first, as I was acquainted with the idea of train and test sets, where the test set is used to validate the training. But in the fastai library, the test set is what is used to submit to kaggle competitions - hence there are no labels - the result is unseen until you get feedback from submitting to kaggle on the test set.
Instead, fastai uses the name valid (val) to refer to the data set you validate your model against.
Some machine learning processes (e.g. CalibratedClassifierCV in “prefit” mode) recommend yet another hold-out set which is often called the validation set - so even more confusing if you are aware of that concept!
Hi all —
I’m running into some trouble predicting on my test set. I’m trying to submit to Kaggle for the MNIST comp. Everything up until now has made sense, but when I actually go to use the model, I’m having issues. I created my dataset:
data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(arch, sz), test_name='test')
I can run it through the fitting without issue, and then I run the prediction step:
mypreds = learn.predict(is_test=True)
mypreds[:4]
Output:
array([[ -8.34568, -15.68095, -15.91709, -17.87472, -16.13111, -13.19016, -0.00024, -18.87988, -12.81165,
-15.99587],
[-12.95259, -7.5127 , -0.01056, -6.33938, -5.02147, -9.44032, -8.79326, -7.38153, -8.1664 ,
-7.68042],
[ -0.00248, -13.80343, -9.84029, -12.51427, -14.83042, -12.32397, -9.07121, -11.57375, -12.00525,
-6.08006],
[-19.11721, 0. , -20.84688, -23.33678, -14.91827, -24.31927, -19.93888, -17.24662, -22.26313,
-17.40252]], dtype=float32)
Checking the shape:
>>> mypreds.shape
(28000, 10)
Checking the actual files:
(fastai) ubuntu@ip-172-31-37-237:~/fastai/courses/dl1/data/mnist$ ls test/ | wc -l
28000
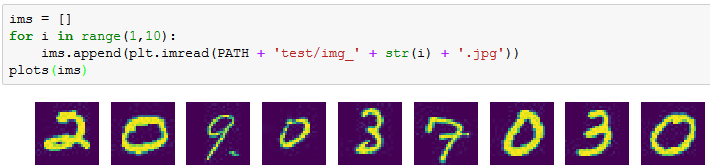
Looks good. However, when I manually check the images, they don’t match the predictions.
>>> preds = np.argmax(mypreds, axis=1)
>>> preds[:10]
array([6, 2, 0, 1, 8, 4, 7, 5, 7, 5])
Compared to:
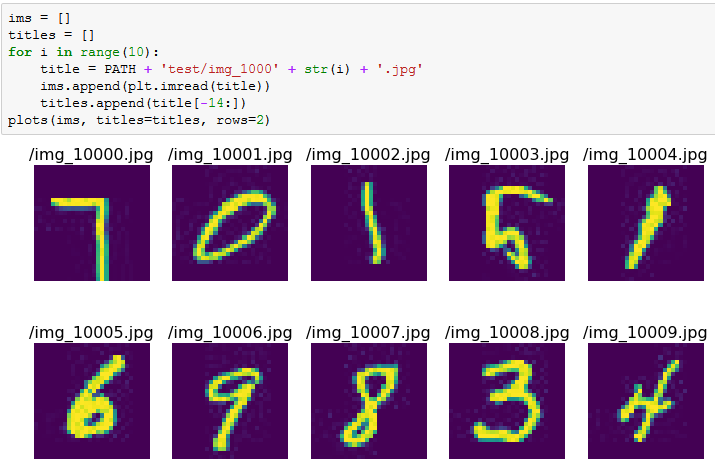
I also checked other files instead of just img_{1,2,3...}.jpg
(fastai) ubuntu@ip-172-31-37-237:~/fastai/courses/dl1/data/mnist$ ls test | head
img_10000.jpg
img_10001.jpg
img_10002.jpg
img_10003.jpg
img_10004.jpg
img_10005.jpg
img_10006.jpg
img_10007.jpg
img_10008.jpg
img_10009.jpg
These are the first files listed in the directory when I browse via command line, so maybe predict is grabbing those?
I tried that, but they still don’t seem to line up. I’ve checked to see if maybe everything is off by one or something, but it still doesn’t work. I feel like I’m missing something obvious, but I’ve searched for a while on the forums and watched the videos several times through, but I’ve missed how to do this. Any help is welcome!
Hey Daniel,
I got the same problem - I don’t know how prediction and test data files match to each other. Just wonder if you have got an solution to this? Thx!
get the list of file names in correct order from the data object
validation files:
data.valid_ds.fnames
test files:
data.test_ds.fnames
Got a error, when I predict test data without labels which are in a folder, ‘test’.
Have any ideas? Thanks
tfms = tfms_from_model(f_model, sz, crop_type=CropType.NO, tfm_y=tfm_y, aug_tfms=augs)
md = ImageClassifierData.from_csv(PATH, JPEGS, BB_CSV, tfms=tfms, continuous=True,test_name=‘test’)
learn.predict(is_test=True)
IndexError Traceback (most recent call last)
in ()
----> 1 learn.predict(is_test=True)
~/fastai/fastai/zeroshot/fastai/learner.py in predict(self, is_test)
278 def predict(self, is_test=False):
279 dl = self.data.test_dl if is_test else self.data.val_dl
–> 280 return predict(self.model, dl)
281
282 def predict_with_targs(self, is_test=False):
~/fastai/fastai/zeroshot/fastai/model.py in predict(m, dl)
135
136 def predict(m, dl):
–> 137 preda,_ = predict_with_targs_(m, dl)
138 return to_np(torch.cat(preda))
139
~/fastai/fastai/zeroshot/fastai/model.py in predict_with_targs_(m, dl)
147 if hasattr(m, ‘reset’): m.reset()
148 res = []
–> 149 for *x,y in iter(dl): res.append([get_prediction(m(*VV(x))),y])
150 return zip(*res)
151
~/fastai/fastai/zeroshot/fastai/dataloader.py in iter(self)
82 # avoid py3.6 issue where queue is infinite and can result in memory exhaustion
83 for c in chunk_iter(iter(self.batch_sampler), self.num_workers*10):
—> 84 for batch in e.map(self.get_batch, c): yield get_tensor(batch, self.pin_memory)
85
~/anaconda3/envs/fastai/lib/python3.6/concurrent/futures/_base.py in result_iterator()
584 # Careful not to keep a reference to the popped future
585 if timeout is None:
–> 586 yield fs.pop().result()
587 else:
588 yield fs.pop().result(end_time - time.time())
~/anaconda3/envs/fastai/lib/python3.6/concurrent/futures/_base.py in result(self, timeout)
430 raise CancelledError()
431 elif self._state == FINISHED:
–> 432 return self.__get_result()
433 else:
434 raise TimeoutError()
~/anaconda3/envs/fastai/lib/python3.6/concurrent/futures/_base.py in __get_result(self)
382 def __get_result(self):
383 if self._exception:
–> 384 raise self._exception
385 else:
386 return self._result
~/anaconda3/envs/fastai/lib/python3.6/concurrent/futures/thread.py in run(self)
54
55 try:
—> 56 result = self.fn(*self.args, **self.kwargs)
57 except BaseException as exc:
58 self.future.set_exception(exc)
~/fastai/fastai/zeroshot/fastai/dataloader.py in get_batch(self, indices)
69
70 def get_batch(self, indices):
—> 71 res = self.np_collate([self.dataset[i] for i in indices])
72 if self.transpose: res[0] = res[0].T
73 if self.transpose_y: res[1] = res[1].T
~/fastai/fastai/zeroshot/fastai/dataloader.py in (.0)
69
70 def get_batch(self, indices):
—> 71 res = self.np_collate([self.dataset[i] for i in indices])
72 if self.transpose: res[0] = res[0].T
73 if self.transpose_y: res[1] = res[1].T
~/fastai/fastai/zeroshot/fastai/dataset.py in getitem(self, idx)
160 def getitem(self, idx):
161 x,y = self.get_x(idx),self.get_y(idx)
–> 162 return self.get(self.transform, x, y)
163
164 def len(self): return self.n
~/fastai/fastai/zeroshot/fastai/dataset.py in get(self, tfm, x, y)
165
166 def get(self, tfm, x, y):
–> 167 return (x,y) if tfm is None else tfm(x,y)
168
169 @abstractmethod
~/fastai/fastai/zeroshot/fastai/transforms.py in call(self, im, y)
519 crop_tfm = crop_fn_lu[crop_type](sz, tfm_y, sz_y)
520 self.tfms = tfms + [crop_tfm, normalizer, ChannelOrder(tfm_y)]
–> 521 def call(self, im, y=None): return compose(im, y, self.tfms)
522 def repr(self): return str(self.tfms)
523
~/fastai/fastai/zeroshot/fastai/transforms.py in compose(im, y, fns)
500 for fn in fns:
501 #pdb.set_trace()
–> 502 im, y =fn(im, y)
503 return im if y is None else (im, y)
504
~/fastai/fastai/zeroshot/fastai/transforms.py in call(self, x, y)
174 x,y = ((self.transform(x),y) if self.tfm_y==TfmType.NO
175 else self.transform(x,y) if self.tfm_y in (TfmType.PIXEL, TfmType.CLASS)
–> 176 else self.transform_coord(x,y))
177 return x, y
178
~/fastai/fastai/zeroshot/fastai/transforms.py in transform_coord(self, x, ys)
205 def transform_coord(self, x, ys):
206 yp = partition(ys, 4)
–> 207 y2 = [self.map_y(y,x) for y in yp]
208 x = self.do_transform(x, False)
209 return x, np.concatenate(y2)
~/fastai/fastai/zeroshot/fastai/transforms.py in (.0)
205 def transform_coord(self, x, ys):
206 yp = partition(ys, 4)
–> 207 y2 = [self.map_y(y,x) for y in yp]
208 x = self.do_transform(x, False)
209 return x, np.concatenate(y2)
~/fastai/fastai/zeroshot/fastai/transforms.py in map_y(self, y0, x)
199
200 def map_y(self, y0, x):
–> 201 y = CoordTransform.make_square(y0, x)
202 y_tr = self.do_transform(y, True)
203 return to_bb(y_tr, y)
~/fastai/fastai/zeroshot/fastai/transforms.py in make_square(y, x)
195 y1 = np.zeros((r, c))
196 y = y.astype(np.int)
–> 197 y1[y[0]:y[2], y[1]:y[3]] = 1.
198 return y1
199
IndexError: index 2 is out of bounds for axis 0 with size 1
There’s no documentation for the fastai package, so we have to dig into the code.
looking at the lesson1 code, where prediction is done from the training data
log_preds = learn.predict()
position cursor inside the brackets, use the SHIFT-TAB-TAB (shift and hold, TAB twice) brings up a screen showing the source file.
then jumping to the source code in github
def predict(self, is_test=False, use_swa=False):
dl = self.data.test_dl if is_test else self.data.val_dl
m = self.swa_model if use_swa else self.model
return predict(m, dl)
if is_test=True then the above will use self.data.test_dl
otherwise uses self.data.val_dl
the if syntax used is explained here
https://docs.python.org/3/reference/expressions.html#conditional-expressions
recall the test data was set by the directory structure when loading data.
data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(arch, sz), test_name=“test”)
refer
def from_paths(cls, path, bs=64, tfms=(None,None), trn_name=‘train’, val_name=‘valid’, test_name=None, test_with_labels=False, num_workers=8):
[figured I’d copy my notes here as this three me initially. others might find it useful]
Hi Guys
I may be late to the party, but hopefully someone will find this useful.
In order to test our trained ANN on the unseen ‘test’ data, the following changes / steps need to be undertaken:
1. Add the ‘test_name’ parameter:
data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(arch, sz), test_name=‘test1’)
log_testpreds = learn.predict(is_test=True)
testprobs = np.exp(log_testpreds[:,1])
testprobs
Yields:
array([0.44364, 0.79223, 0.94982, 0.99699, 0.84098, 0.03484, 0.88222 …
Notes:
My test data included images named: 0001.jpeg, 0002.jpeg, 0003.jpeg, … etc. With the 0001-0030 being dolphins, and 0031 - 0060 being sharks (Sharks and Dolphins as opposed to Dogs and Cats).
I noticed that my probabilities didn’t at all match my images in the test set. My results looked like complete guesswork; no better than 50% accuracy. A shark-fin and dolphin-steak salad! This seemed strange, since my validation accuracy was 93% . So I created a test set containing 1 image. It was correctly classified. I then tested on another single image. Also correct. I repeated this a few times and always got the correct classification. So I did some examination:
test_files = os.listdir(f’{PATH}/test1/’)[:]
test_files
Yields a random order of images.
[‘0001.jpeg’,
‘0037.jpeg’,
‘0030.jpeg’,
‘0040.jpeg’,
‘0027.jpeg’,
‘0043.jpeg’,
‘0025.jpeg’ …
I checked on this and found the following: os.listdir order in python
os.listdir(path)
Return a list containing the names of the entries in the directory given by path. The list is in arbitrary order. It does not include the special entries ‘.’ and ‘…’ even if they are present in the directory.
So I matched the correct image up to the correct probability (in excel):
0001.jpeg - 0.44364
0002.jpeg - 0.03068
0003.jpeg - 0.00579
…
0037.jpeg - 0.79223
And got the expected accuracy of 93%
I’m a newbie and been taking the course online and was wondering the same thing but it looks like you need to use data.classes to look up the actual class being predicted, so assuming you’ve named your ImageClassifierData “data” and done the below steps:
log_preds = learn.predict(is_test=True)
preds = np.argmax(log_preds, axis=1)
Then, you can use the following type of loop to get the filenames, predicted classes and percentage prediction.
itemIndex = 0
for maxIndex in preds:
print((data.test_ds.fnames[itemIndex],
data.classes[maxIndex],
np.exp(log_preds[itemIndex][maxIndex])))
itemIndex = itemIndex + 1
Hope this helps.`
I just want to point out that the test dataset has wrong labels:
log_preds, test_labels = learn.TTA(is_test=True)
np.mean(test_labels) # Mean is 0, labels are wrong!!!!! The test images are not all cats.
learn.TTA returns log_pred and labels if is_test =False else it gives {zeroes} for labels. You can check this by pressing SHIFT+{TAB TAB}.
If you want to check mean of test according to what your classifier predicted. You should use:
preds = np.argmax(log_preds, 1)
preds.mean()
Does that make sense? Why not return labels for the test set? It is inconsistent and renders the test set useless.
You are getting confused between labels and predictions. Labels are what they actually are while predictions are what we predict them to be. Labels are not provided for test dataset.
No, I am not confused at all. Labels are the truth, predictions are what the model thinks is the truth.
I am just pointing out that making predictions on the test dataset without being able to find out the accuracy doesn’t make sense and returning a list of all zeros is misleading and wasteful.
If your “Test” data set doesn’t have labels then all that can be returned is the predictions. And contrary to your statement, it does make sense to do this, for example, if you enter a Kaggle competition you will get a “Test” set without labels on which you will need to make predictions for submission.
Well, you are following a course, not in a kaggle competition here, right?
If the intention is to (unnecessarily) hide the labels, then at least return None instead of all zeros, because that’s wrong and misleading.