I found incomplete predictions too and I think it’s because of the rounding when splitting data into batches. My hacky solution is too append some redundant data at the end of the dataframe so that it won’t cut my real data.
Another thing I noticed is that there may be some shuffling involved in the batches and as a result the prediction output do not follow the original order. This is very annoying and my (another) hacky solution is to set the prediction batch size to 1 to preserve the original order.
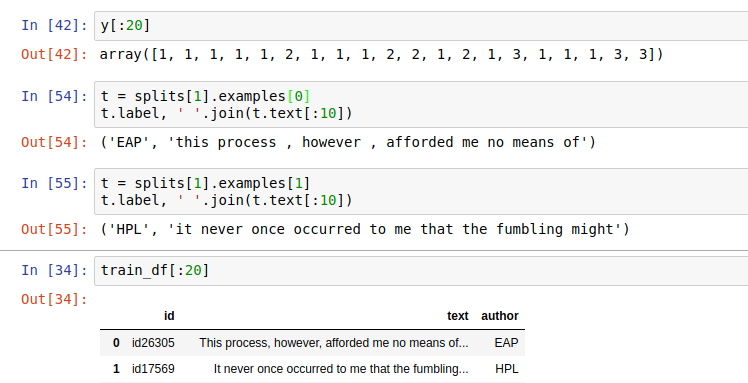
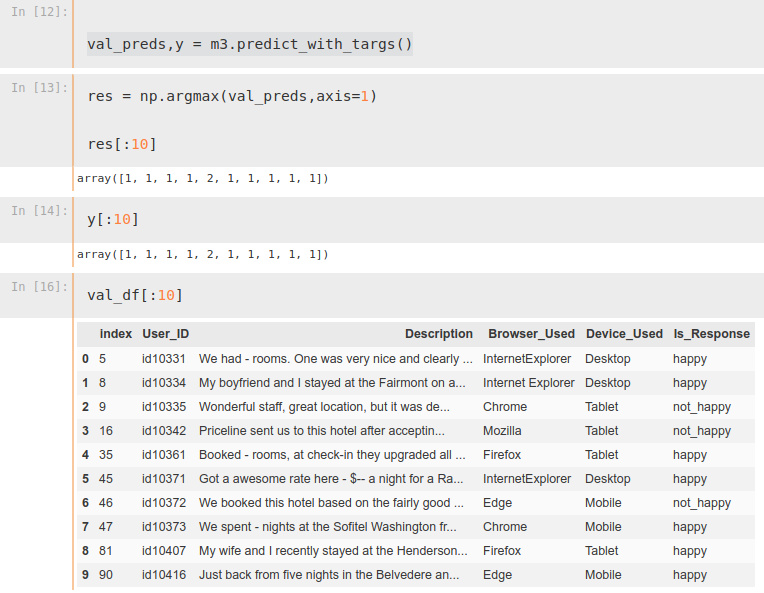
y is supposed to be the actual targets … but notice that the first two are both 1’s. And yet, when you look at the first 2 examples in my validation datasets (btw, I’m using my training as my validation dataset for testing), the actual classes cannot both me 1.
You can see from the source code here that torchtext.data.BucketIterator.splits actually takes in a batch_sizes tuple argument that defines batch sizes for different datasets.
Yes, if no shuffling is involved, torchtext sorts data by the word length of the text object (because we define sort_key as def sort_key(ex): return len(ex.text), as in cell 115 of this notebook), and in the case of ties, it breaks them by preserving the original order. So I would sort my data by those two factors too. It does that because it tries to group texts with similar lengths together in a batch to feed into the model.
Did you try to sort val_df by text length as discussed above? I might have missed it in your notebook but this is what I did (my dataset is called txt_test and my text column is text):
# Sort by len
# Because that's how torchtext would sort it,
# Hence need to do the same in order to match its results
txt_test['text_toks'] = txt_test['text'].apply(spacy_tok)
txt_test['text_len'] = txt_test['text_toks'].str.len()
txt_test['index'] = txt_test.index # Note this is assuming that the data is already sorted by index; if that's not true, use `.iloc` instead
txt_test.sort_values(by=['text_len', 'index'], inplace=True)
txt_test.reset_index(drop=True, inplace=True)
Btw, here is my full notebook, which I hope is right.
FYI as I’m sure you’ve noticed, I haven’t used a test set with this class before - sorry about the shuffling thing! I’m working on tomorrow’s class at the moment so won’t be able to debug right away, but if you want to do so, try looking at how torchtext is handling this. I’m not sure if the issue is in torchtext, or just how I’m calling it.
Both torchtext and fastai are pretty simple code to read - hopefully it’ll be reasonably clear what’s going on. Let me know if I can help clarify anything!
@KevinB was able to get a submission into the Happiness competition, so I think he has something that works, and I don’t think it’s as complicated as we are making it. Perhaps he can enlighten us when he has a chance.
If you look at the source code for BucketIterator here, you can see that it always sorts (even if you set sort=False. That simply, shifts the sorting to happen in the batches.
So all I did is use what Jeremy did in his lesson 4 notebook to predict what the sentence will be. I set my batchsize to 1 and I pulled the text from the CSV file directly. Then I just looped through those one at a time and tied them to a file. Then I just chose the top prediction and converted it from the index to the actual word. Is there any specific code/questions you are wondering about?
m = m3.model
m[0].bs = 1
for i in range(tst.values[:,1].shape[0]):
ss = tst["Description"][i] #Actual text review
s = [spacy_tok(ss)]
t = TEXT.numericalize(s)
m.eval()
m.reset()
res,*_ = m(t)
prediction = PH_LABEL.vocab.itos[to_np(torch.topk(res[-1], 1)[1])[0]]