ok, I’m almost there, I’m starting to get the list I want, although some questions remain.
This is the code I run in Lesson 1 after the first training round:
Which gives an output per following:
(‘valid/down/snaps177787_-1.png’, ‘down’, array([0.93993, 0.06007], dtype=float32))
(‘valid/down/snaps177787_-1.png’, ‘down’, array([0.93993, 0.06007], dtype=float32))
…(one line for each file)
Note that the file name is always the same, which is not correct because there are 684 files in this directory. The second parameter is sometimes ‘down’, sometimes ‘up’ , which is possible, the last parameter, array, is only giving two pairs of numbers, which does not seem right.
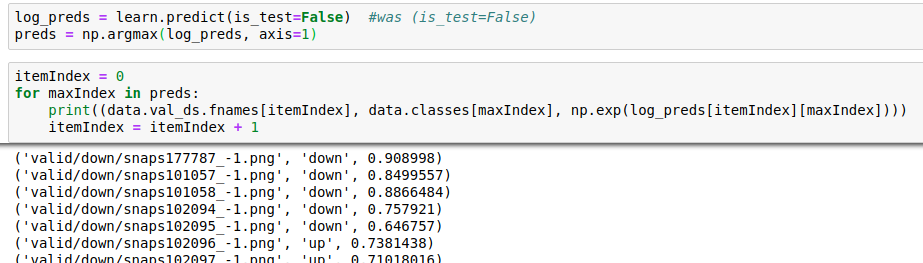
If I modify my code by increasing the indent of the last line (itemIndex = itemIndex + 1), then I get the following output:
(‘valid/down/snaps177787_-1.png’, ‘down’, array([0.93993, 0.06007], dtype=float32))
(‘valid/down/snaps101057_-1.png’, ‘down’, array([0.93993, 0.06007], dty
Which seems better because the file name is changing, although the array parameters are not, I also get an error message after 5 lines:
IndexError: index 5 is out of bounds for axis 0 with size 5
I’m getting close I think.