I’m having some trouble seeing how embedding matrices are learned. If I understand Jeremy correctly, after having extracted some categorical variables corresponding embedding vector, we concatenate it to the vector of continuous variables and treat the whole thing as input to a neural network. In the paper Entity Embeddings of Categorical Variables the authors similarly state:
“After we use entity embeddings to represent all categorical variables, all embedding layers and the input of all continuous variables (if any) are concatenated. The merged layer is treated like a normal input layer in neural networks and other layers can be build on top of it. The whole network can be trained with the standard backpropagation method. In this way, the entity embedding layer learns about the intrinsic properties of each category, while the deeper layers form complex combinations of them.”
What stumps me is the following: If the embedding vectors are now inputs, how do we learn them? Normally, we learn the weights associated with the inputs, but here the weights seem to be the inputs themselves. How can they then be updated?
I think you have it right, they are treated as weights and you can back propagate into them just like any other layer.
Consider the case where you have only one categorical variable as input to a net and you’ve one hot encoded it. The first “layer” in the net is the dense embedding matrix; in this situation it is identical to a dense layer in a net and so you can train it like one.
Because of the one hot encoding, a given input only interacts with a single row of this first dense layer, so you can interpret each row of weights as the inputs into the rest of the network, e.g. the one hot encoding just maps you to a particular row aka input into the net.
Yeah, I totally follow your example, but my intuition breaks down as soon as we concatenate the embedding vector to the the continuous variables and treat them as inputs.
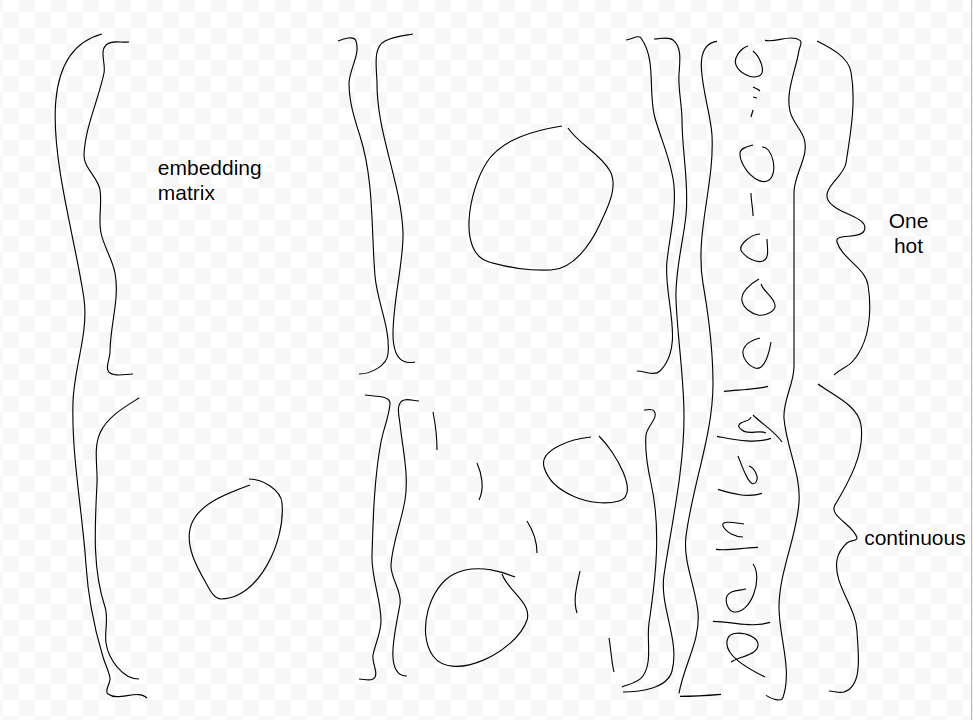
So in my terrible picture, I am representing the first layer as a matrix vector multiply. The input vector on the left is a one hot encoding of a categorical variable and we’ve concatenated the continuous variables on the bottom. The matrix is a sparse block matrix; the off diagonal blocks are all zeros. The top left diagonal block is the embedding matrix associated with the categorical variable, and the bottom right block is just an identity matrix. The output of this guy is the categorical variable encoded, and the continuous variables passed through. If we treat this block matrix as a layer in the network, you can learn the embedding only and keep the 0 blocks and identity blocks frozen so that those “weights” don’t change. The output of this layer is then just fed to the next layer in the net per usual. Hope that helps!