Has anyone tried anything on one of these new cards?
1 Like
I doubt anyone has received one yet! But the p3 instance on AWS is nearly the same thing.
1 Like
you wouldn’t happen to have compared timings on a decent size model running in half precision on P3 (V100) vs single precision on a 1080 ti by chance?
I haven’t, but would be v interested to see such a thing.
I have one on pre-order from Nvidia in Sweden, though it will not ship before Dec 30 here.
TBH, I’m hoping to read some real-life benchmarks for PyTorch/TensorFlow before that.
Some folks on KaggleNoobs (including the Kaggle wunderkind Anokas, aka Mikel Bober-Irizar) are suspecting that its “110 TFLOPS” claim is actually just a “14 TFLOPS” by standard metrics used for other cards.
https://kagglenoobs.slack.com/archives/C3NH0MF9R/p1513013405000111
But if the specs are true, this would be a serious card for anyone with a personal workstation not wanting to go down the path of Multi-GPUs, like 3x 1080Ti as that implies some serious hardware investment on top (Enterprise-level CPU, MotherBoard, PowerSupply, RAM size et al.)
1 Like
That link needs an account - any chance you could copy his comments here?
I think the KaggleNoobs account is fast to open/validate, plus it’s a great community re. Kaggle discussions.
I’m sure you’ll be more than welcome as a guest of honor 
Just in-case as per your request (and please remember that this section of Fast.ai is private so they can’t read/respond to it), here’s a mixed copy/paste of some comments.
The marketing on the Titan V kinda frustrates me. It’s a 14TFLOP card (by the metric all the other cards are measured) but it gets 110TFLOPS on one specific operation in half-precision - so that’s what they put on the marketing material (edited)
Yeah, it got me. Bamboozled…
Tbh I wasn’t expecting a 3k card either.
Would it be better to buy 3 1080ti’s?
Yeah. But the fact that it took me 10 minutes of searching to even find out what the true TFLOPS of the card is ridiculous. Borderline false marketing
it reminds me of false marketing of 970, where they did not say that not all of the card’s 4GB has the same speed …
There are more discussion following around “Multi-GPU 3/4x 1080TI” vs. “Single Titan V” but copying/pasting them here would somehow take out the context.
E.
Thanks for the info. The one op he refers to is the most important op for DL, so you may find very large performance improvements as a result.
Since the Titan V is comparable to a V100 and the 1080 Ti is comparable to the P100, the V100 vs. P100 benchmarks already available should give a good idea of the relative performance between the Titan V vs. 1080 Ti.
There are certainly cases where the V100 is more than 3x faster than the P100 (CNNs during inference). I’d expect for those same workloads, a single Titan V to outperform 3 1080 Tis.
For workloads which can’t utilize the Tensor Cores much, like training an RNN, I doubt a Titan V will outperform 3 1080 Ti cards.
Of course, if you have a pure FP16 matrix multiplication workload, the Titan V really should be at least 8x the performance of a 1080 Ti.
Pytorch supports using the tensor core for RNNs AFAICT.
The benchmarks you should look at in general are for half precision. It seems single precision GEMM is supported on Volta, but not currently enabled in Pytorch. I’ve just contacted the pytorch team to ask about enabling this.
I believe you’re right, but AFAIK, matrix multiplications make up a much smaller percentage of the operations in RNNs compared to CNNs.
Here’s the V100 vs. P100 (relative to the P100). I expect the Titan V have similar numbers compared to the 1080 Ti.
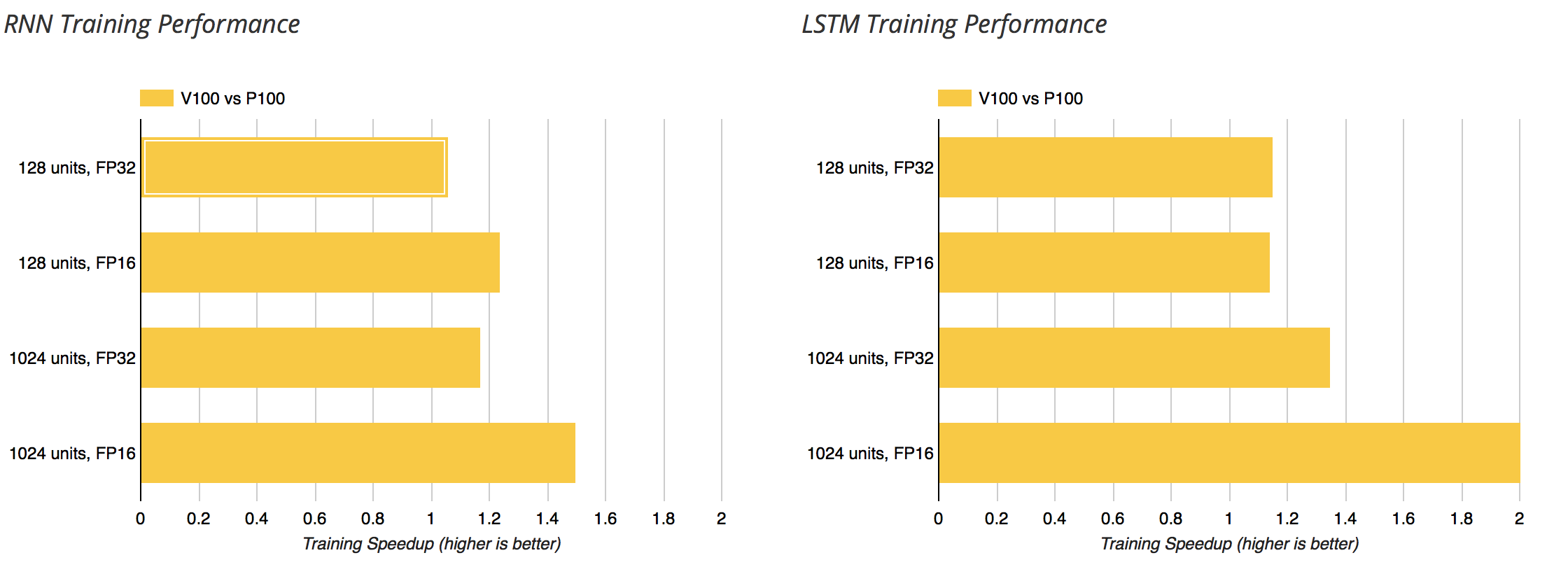
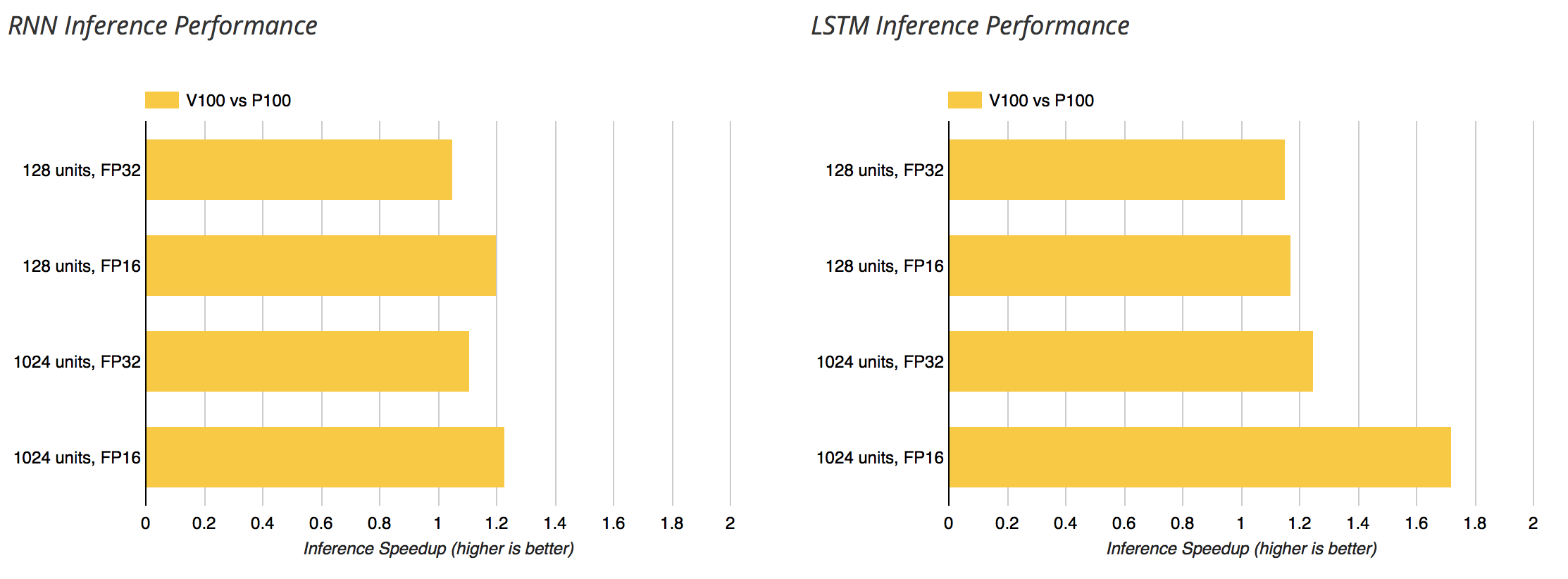
AFAIK, while they do not have ‘tensor cores’, P100’s support half precision compute (they report half precision TFLOPs at ~2x their single precision). Unless there’s been some release I missed, 1080 ti’s (nor anything below the P100s) do not support this (their top performance is in single precision). If I’m understanding the capabilities correctly, there might be an additional multiplier when comparing to the 1080 ti.
I’m not sure what you mean. RNNs are basically entirely matrix multiplications. And with QRNN, they’re even more suitable for acceleration.
Hmm. Perhaps I misunderstand.
Last time I profiled an RNN (which admittedly was a while ago), the non-mm operations like vecadd ate up a tremendous amount of wall time. It wasn’t that those operations were all that intensive, iirc, it was that the memory loads were so slow.
Unless I’m totally misunderstanding something, I would assume that the time spent doing matrix multiplies to everything else including memory loads is lower in an RNN compared to a CNN.
Ah well that’s a good point. I suspect with modern approaches (multi layer, bidir, attention) and the HBM memory that may not be so true any more. Especially with QRNN. I’m not sure though - I’d love to see benchmarks.
According to this benchmark, your expectations are correct @aloisius https://www.xcelerit.com/computing-benchmarks/insights/benchmarks-deep-learning-nvidia-p100-vs-v100-gpu/ . I’m not sure if they used the cudnn RNN op for this however.
1 Like
Here’s another benchmark, from Dell HPC, on the V100 vs P100, including PCIe versions, running ResNet50 on NV-Caffe, MXNet and TensorFlow, done in October 2017.
And also another blog post here.
The keyword seems to be Mixed Precision Training here and the post includes two links to research articles from Nvidia and Baidu.
(Links courtesy of Anokas twitter account https://twitter.com/mikb0b/status/940271947316912128)
Someone opened a ticket on PyTorch Discuss forum, re. poor performance of the Titan V vs 1080 Ti.
Probably the first ML comparison (there are Gaming benchmarks already, not so positive for the Titan V, in performance per dollar, but is that its main task ?).
It was answered by a PyTorch Dev with some code fixes, though I’m not sure if this is representative/final for the Titan V and its unique combo of Tensor Cores + Mixed Precision Training, vs the 1080 Ti or Titan Xp.
1 Like
I don’t think this is using the tensor cores at all - there’s quite a bit more to do to get that working.
A post from Tim Dettmers (" Which GPU for Deep Learning") on the Titan V and incoming competition from Intel & AMD.
The more I read about the “abysmal/poor value” of the Titan V for $3000, the more I wonder how come the original Tesla V100 at $10K could find a market in the first place.
Am I missing something ?
1 Like