One thing I miss is a way to keep track of different runs. Not only results, but also all the training history of a specific model.
2 Likes
Thanks @sgugger for the reply.
I thought TextDataset is same as before, which can be created from numpy arrays of ids (int representation of text) directly. However, I think this is no longer possible. So, DataBunch.create(train_ds, valid_ds,…) is not very useable.
I think with current fastai V1 it is not possible to create DataBunch using the data (Tokens, ids) directly. Only folders-based options are available to create these objects (DataBunch, TextDataset etc). Imagine someone want to run a text classifier on a few different samples of data, then the folder based options will not be very useful as he has to create and save all those samples in the folder. Every time he wants to change data, increase-decrease label data, create new samples, or modify data, he has to save all those snippets of data in the folder in order to create DataBunch. Is there any way that with current library we can handle such scenarios (create DataBunch directly from numpy arrays)? I think this is very practical need in many experiments and tests.
It’s already possible to create a TextDataset from folders, a dataframe, a csv file, token files or id files (save of a np.array containing the ids), as explained in the documentation.
As for creating a DataBunch there is a function for each of those methods.
Yes, but I think all of these method requires the path of the files ( path to csv file, path to token files or id files). Let’s imagine I have created these objects (train_ids, train_labels, valid_ids, valid_labels, itos.pkl) which are currently in memory. Can we create TextDataset from these in memory objects without saving them on hard disk?
I am with this exact problem. I am trying to update some notebooks I have to v1. My corpus is the longest 2% articles of wikipedia in portuguese and it is running out of memory.
1 Like
Not yet no. That would require a class over TextDataset like BasicTextDataset. I’ll add it sometime soon.
1 Like
That will be great.
Just been added in my last commit. Look for the from_ids factory method (instead of from_id_files).
1 Like
Wonderful. Thanks.
One other thing, is the fastai V1 library has no backward compatibility? I have created a language model previously where encoders were save as .h5 extensions. In the current library, it expects .pth extension encoders. I renamed my previously build Language Model encoder to have .pth extension but it throws this error.
RuntimeError: Error(s) in loading state_dict for MultiBatchRNNCore:
Missing key(s) in state_dict: "encoder_dp.emb.weight", "rnns.0.weight_hh_l0_raw", "rnns.0.module.weight_hh_l0", "rnns.1.weight_hh_l0_raw", "rnns.1.module.weight_hh_l0", "rnns.2.weight_hh_l0_raw", "rnns.2.module.weight_hh_l0".
Unexpected key(s) in state_dict: "encoder_with_dropout.embed.weight", "rnns.0.module.weight_hh_l0_raw", "rnns.1.module.weight_hh_l0_raw", "rnns.2.module.weight_hh_l0_raw".
Is there any way to load previously build encoder in the current library?
No backward compatibility, no, but you can match the keys expected by your new model with the ones of the old. If you create a dictionary of weights with the good keys, you’ll be able to load it and it will work (I double checked for some of the old fastai models).
Here "encoder_with_dropout.embed.weight" should be replaced by "encoder_dp.emb.weight", then the "rnns.{i}.module.weight_hh_l0_raw" should be replaced by the two keys: "rnns.{i}.weight_hh_l0_raw" and "rnns.{i}.module.weight_hh_l0"(model expect the same weights for both as it’s linked to the weight dropout).
2 Likes
Okay thanks I will try this out. I think for backward compatibility, one simple function can be added that does this. It will allow people to use their already build models in fastai V1.
Edit:
What about 1.decoder.weight and 1.decoder.bias ?? I think the old models does not have decoder part. I think they are saved separately?
Here is the function that does this. You might want to add this to the new Library.
def convert(path_to_old_model, path_to_save_converted_model):
"""
path_to_old_model is the path to old model
and
path_to_save_converted_model is the path where the converted model is stored
"""
old_wgts = torch.load(path_to_old_model, map_location=lambda storage, loc: storage)
new_wgts = OrderedDict()
new_wgts['encoder.weight']=old_wgts['0.encoder.weight']
new_wgts['encoder_dp.emb.weight']=old_wgts['0.encoder_with_dropout.embed.weight']
new_wgts['rnns.0.weight_hh_l0_raw']=old_wgts['0.rnns.0.module.weight_hh_l0_raw']
new_wgts['rnns.0.module.weight_ih_l0']=old_wgts['0.rnns.0.module.weight_ih_l0']
new_wgts['rnns.0.module.weight_hh_l0']=old_wgts['0.rnns.0.module.weight_hh_l0_raw']
new_wgts['rnns.0.module.bias_ih_l0']=old_wgts['0.rnns.0.module.bias_ih_l0']
new_wgts['rnns.0.module.bias_hh_l0']=old_wgts['0.rnns.0.module.bias_hh_l0']
new_wgts['rnns.1.weight_hh_l0_raw']=old_wgts['0.rnns.1.module.weight_hh_l0_raw']
new_wgts['rnns.1.module.weight_ih_l0']=old_wgts['0.rnns.1.module.weight_ih_l0']
new_wgts['rnns.1.module.weight_hh_l0']=old_wgts['0.rnns.1.module.weight_hh_l0_raw']
new_wgts['rnns.1.module.bias_ih_l0']=old_wgts['0.rnns.1.module.bias_ih_l0']
new_wgts['rnns.1.module.bias_hh_l0']=old_wgts['0.rnns.1.module.bias_hh_l0']
new_wgts['rnns.2.weight_hh_l0_raw']=old_wgts['0.rnns.2.module.weight_hh_l0_raw']
new_wgts['rnns.2.module.weight_ih_l0']=old_wgts['0.rnns.2.module.weight_ih_l0']
new_wgts['rnns.2.module.weight_hh_l0']=old_wgts['0.rnns.2.module.weight_hh_l0_raw']
new_wgts['rnns.2.module.bias_ih_l0']=old_wgts['0.rnns.2.module.bias_ih_l0']
new_wgts['rnns.2.module.bias_hh_l0']=old_wgts['0.rnns.2.module.bias_hh_l0']
torch.save(new_wgts, path_to_save_converted_model+'converted_model.pth')
2 Likes
I don’t know whether this was suggested or not. But It will be nice to have options which along finding learning rate will also grid search few weight decays very similar to the figure from Smith paper.
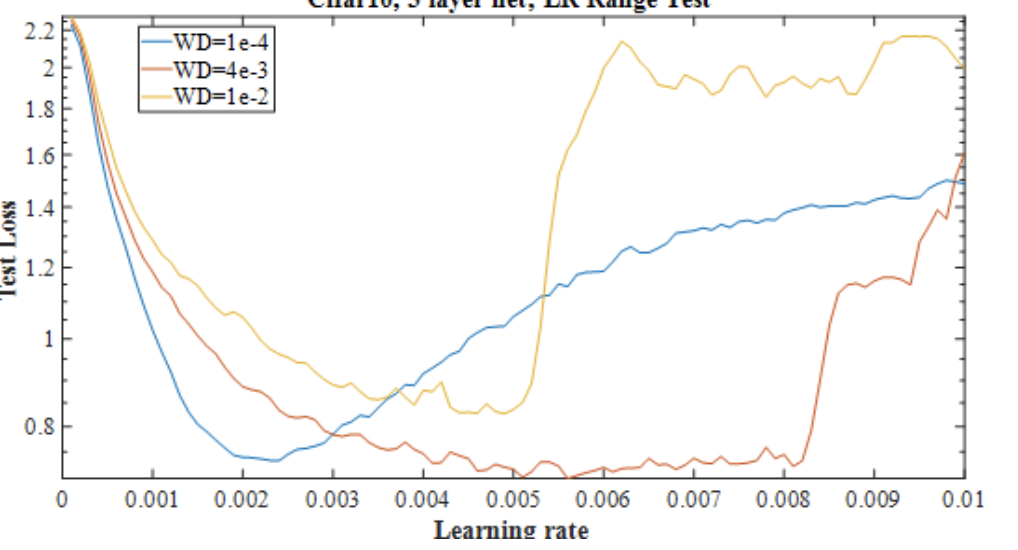
I made something quick for my self. It currently called wd_finder And plotting function plot_wd looks something like this.
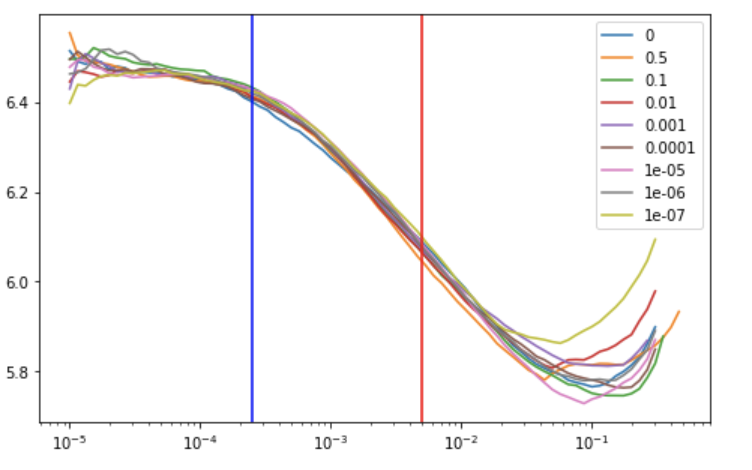
If people are interested I can share the notebook and we can add it to the library.
2 Likes
Do you have it in a public notebook somewhere? github repo?
1 Like
I will clean up the code, and share GitHub repo=)
1 Like
Here is link to repo… One could improve progress bar… Hope it helps!
the function at the end creates following graph (using standard wd or provided by users)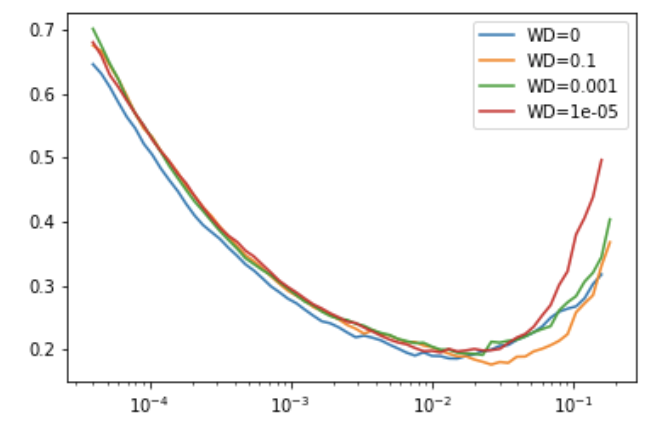
3 Likes
I was looking into the codebase and noticed that spacy tokenizer is initialized like this. https://github.com/fastai/fastai/blob/68466b5268d5c7a6c42389798f9bb7daf0154139/fastai/text/transform.py#L23
In order to leverage alpha tokenization support for other languages as well (https://spacy.io/usage/models#alpha-support), what do you think about initializing as follows:
try:
self.tok = spacy.load(lang)
except Exception:
self.tok = spacy.blank(lang)
1 Like
Good point, there’s actually no point using spacy.load(lang) for the tokenization, so we switched to spacy.blank(lang).
1 Like
this is a really good idea
1 Like
Minor feature request: consistent data load function behavior with regard to file names.
Small thing, but from_csv, from_df, and from_folder expect file paths to images that are relative to path, but from_name_re, from_name_func, and from_lists require absolute file paths, even though path is also one of the arguments to all of the ImageDataBunch data loading functions. As a new user of the library I found it confusing and expect other new users may as well.