IMO, top 8% is awesome! It shows how powerful the techniques taught in this course are.
There was someone else in this forum who mentioned this whole averaging the predictions out for all these architectures and then reaching the top 5% in the fisheries competition. I would definitely want to try that out.
And about manually labelling the dataset why would anyone do that and get themselves disqualified is beyond me but still possible.
Think averaging predictions from the same model on different splits of the data was the right move, but if I had had more submissions (and had left a holdout set), I would want to try something more advanced to combine different model results - maybe stacking?
Might be useful if we cover ensembling in one of the lectures in part II.
I had a similar method and score, although now I’ve dropped down to 9% with the surge of last minute entries.
I used 9-fold splits and averaged across a vgg16 configuration with no dropout. I tried that early on and that was the best I ended up with. I tried ResNet50 but didn’t have much luck with the model there, although I didn’t try the 400x400 size.
Like @radek I totally got caught up with the ‘just one more epoch’ attempts, and also found that I spent a lot more time fiddling with the clipping than I probably should have.
I also tried taking the earlier model layer outputs (the first 4096) and feeding that into xgboost to see if it could come up with a better model. The model it built claimed 99.54% accuracy on 5 fold cross validation but when I submitted the results weren’t as good as my ensemble. I’m not sure what went wrong there.
Looking forward to taking these learnings and moving on to the fisheries competition.
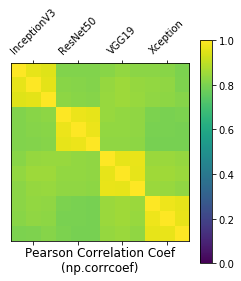
Took a closer look at how correlated the predictions from each of the models were going into the ensemble (3x repetitions per model). Not a lot of variance between repetitions so probably diminishing returns there for the ensemble, but definitely something to gain from using multiple models.
I have a general question about validation - how do you guys make your validation data?
For statefarm, it requires a little more work to have separate drivers in training vs validation set.
For dogscats and fisheries, do you guys just make a one-time setup to make training and validation folders?
Or do you use something liker Keras’ validation_split during training?
I use keras validation_split on every category’s folder and copy from there to a valid and training folders (I keep the original data untouched as train_orig), then in my for-loops I copy a fraction of the data to a sample folder with the same train/valid/test structure. I use 10% of the original data for a sample and a 75% or 85% training/validation split.
import os
import shutil
from sklearn.model_selection import train_test_split
#path=os.path.realpath('')+'/'+path
# cats/dogs
pre_run=0
samplesize=0.1
prop_train=0.75
if(pre_run==1):
shutil.rmtree(path+'sample',ignore_errors=1)
shutil.rmtree(path+'valid',ignore_errors=1)
shutil.rmtree(path+'train',ignore_errors=1)
os.mkdir(path+'sample')
os.mkdir(path+'valid')
os.mkdir(path+'train')
os.mkdir(path+'sample/train')
os.mkdir(path+'sample/test')
os.mkdir(path+'sample/valid')
dirs=glob(path+'train_orig/*')
for i in dirs:
subdir=i.split('/')[-1]
os.mkdir(path+'sample/train/'+subdir)
os.mkdir(path+'train/'+subdir)
os.mkdir(path+'sample/valid/'+subdir)
os.mkdir(path+'valid/'+subdir)
train,valid=train_test_split(os.listdir(i),train_size=prop_train,random_state=42)
count=0
for j in valid:
if count<=samplesize*len(valid):
shutil.copy(i+'/'+j,path+'sample/valid/'+subdir+'/'+j)
count+=1
shutil.copy(i+'/'+j,path+'valid/'+subdir+'/'+j)
count=0
for j in train:
if count<=samplesize*len(train):
shutil.copy(i+'/'+j,path+'sample/train/'+subdir+'/'+j)
count+=1
shutil.copy(i+'/'+j,path+'train/'+subdir+'/'+j)
test_imgs=glob(path+'test/*')
np.random.seed(42)
sample_test=np.random.permutation(test_imgs)[:round(len(test_imgs)*samplesize)]
for i in sample_test:
shutil.copy(i,path+'sample/test/'+i.split('/')[-1])
In the case of, e.g. fisheries, do you make your validation set same distribution of classes as training set?
E.g. 10% of each class, or would we want a more random distribution so as not to overfit?
I am having trouble to tell when/if my models are overfitting to training/validation data.
E.g. fisheries, using Dense(256, activation='relu') in the FC layers, I find that validation loss goes down much faster than training loss. Could it be that my model is overfitting to validation data?
It is impossible to overfit validation set while having poorer results on the training set. The reason for the loss discrepancy you describe is that the loss on the training set includes additional loss through regularization (l1, l2 penalties, loss through dropout etc), so having good performance on the validation set is a good thing
Just to test your sanity (and mine ;)) you might want to take your model and run model.evaluate_generator on your train set. This should give you a lower loss than it gives you during training (I believe at least). The data will still be the same, but the loss will be calculated in the way it is calculated on your validation set during training (or at least I suppose so).
Scikit Learn has a bunch of great CV tools including ShuffleSplit and KFold and stratified versions of both (i.e. Keep class distributions equal).
I did something slightly hacky to make things work without tweaking the Keras image data generator - created file lists with sklearn and then created different folders (i.e. cv_0, cv_1, etc) each containing their own respective train and validation folders.
I put links to the original files (os.symlink) and then used the Keras generator with follow_links=True.
I did something slightly hacky to make things work without tweaking the Keras image data generator - created file lists with sklearn and then created different folders (i.e. cv_0, cv_1, etc) each containing their own respective train and validation folders.
I put links to the original files (os.symlink) and then used the Keras generator with follow_links=True.
That’s a really clever approach. I thought about doing something similar but didn’t know how to do the linking. Do you mind sharing your code? That seems like a really useful technique. I really don’t like the way the keras generator acts only on directories as it makes data manipulation for kfold really difficult. This seems like an elegant solution.
The talk and lecture are awesome, and I love the idea, but I’m not sure I have the chops to implement this, and in digging around I can’t seem to find any examples of anyone using this method that they’ve shared online. Do you know of any examples?
I looked into maybe modifying the softmax layer of Keras to include temperature and I think I could handle that part of it, but I’m a little shaky on the later backpropegation steps and the changes you need to make to the bias.
Overall the concept seems really powerful, particularly for knowledge transfer learning, but I can’t quite figure out the modifications necessary to train the new net so that it’s optimizing the logits of the softmax layer.
Well - this is my first run at deep learning - I did manage to submit to Kaggle for the Dogs and Cats redux - but I missed the end of the competition by 2 days.
Kaggle still gives me a public score, though I don’t believe it gets shown on the leader-board. I came in at 0.10643 which I believe would have been in the top third. Woot!
This first lesson has been a ton of learning - can’t wait to keep digging in. The biggest challenges for me are figuring out the Command Line Interface (though I am starting to feel like a pro at tmux…at least in my own mind) and understanding python commands. (C++ is what I normally code in, and I am only so good at it).
But the experience has been a blast.
On a side note, there were only about 1300 participants in the Kaggle dogs vs cats redux competition. Not as many as I had expected (though I am not sure what I expected).
In any case - thanks to everyone who built this course and has contributed here - what fun!
In the course I show an end to end process for MNIST that includes both ensembling and pseudo-labeling using “dark knowledge”.
Sorry @jeremy, I ran through a number of the lectures again looking for the section you’re talking about and the closest I could find was the start of lecture 6 where you talk about ensembling and pseudo labeling and I checked the mnist code but it doesn’t contain what I’m referring to.
My understanding after watching Hinton’s talk on dark knowledge is that what he refers to as ‘dark knowledge’ is the resulting vector from the shifting of a softmax layer’s outputs via a temperature so that the relationship between objects is much clearer. The vectors he shows at around 11:35 in the lecture are the idea i’m driving at. By training a new net on those soft predictions and a subset of hard targets he’s able to get some very interesting results.
I think there’s a chance we’re talking about different things unless I’m misunderstanding.