I fired up an AWS instance and then tried to download data set from kaggle using kaggle-cli but it I am unable to download the data into my instance. Those who are able to download data please help me.
After I enter the jupyter notebook command in my terminal window( which was connected to aws instance via ssh), If I need another terminal window which is also connected to same aws instance IP how to get it ?
Thanks.
there are many people in this thread who are talking that with ensemble they have got better accuracy and lower loss.what i have understood in simple way that it nothing but grouping two model together and then using it to get better results.
so ,how can i learn this ensemble,and use it with fastai library further reduce loss from my model
any guidance towards it people
restart notebook, run all the stuff once again and it should be normal. Once you have an error during model training, you gonna have this “detailed” status bar
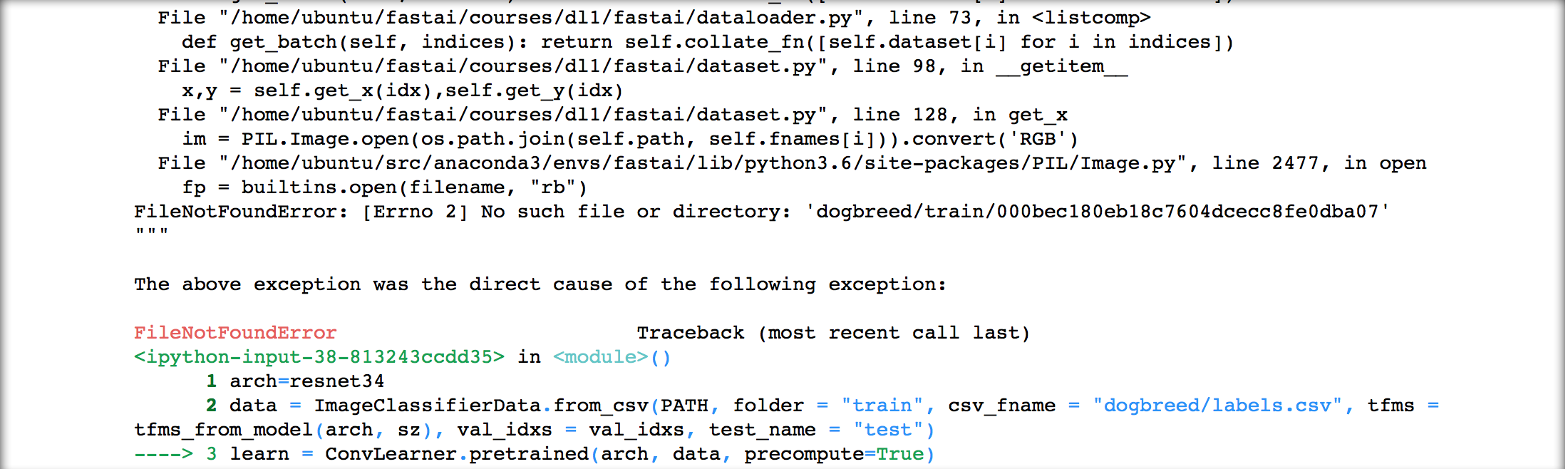
As you pointed out from_csv calls csv_source which gets the paths to the images by doing the following:
Call parse_csv_labels to extract file names, e.g. 000bec180eb18c7604dcecc8fe0dba07, from the csv file. The file names are returned in an array called fnames.
Join folder (e.g. train) with each item in fnames (e.g. 000bec180eb18c7604dcecc8fe0dba07) and suffix (e.g. .jpg). This gives us full_names, the array of the relative paths to the images.
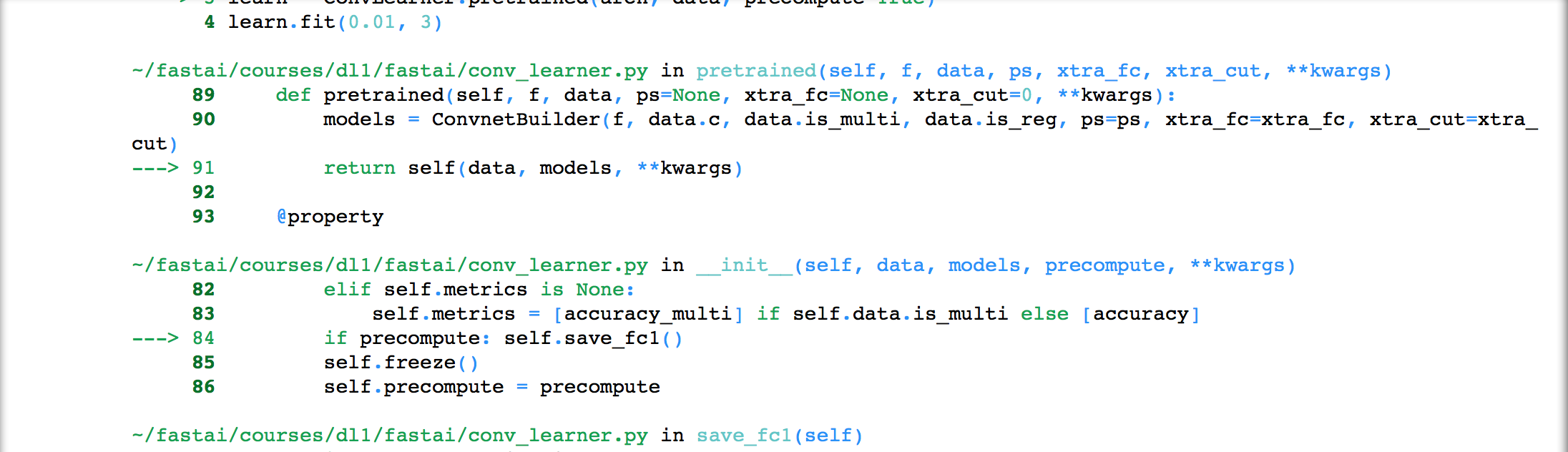
After calling csv_source, from_csv does the following:
Combine path (whatever you set PATH to before you passed it into the function) with the test_name (e.g. test) and get all the files in that path and store that in test_fnames (see how read_dir works)
Pass path and the relative paths to our training images (the two pieces of information we need to be able to access the images), test_fnames, etc. to get_ds. This gives us our datasets for our training images and test images.
How to train on full training data, passing val_ids = None is giving errors.
Also log_preds_tta,y = learn.TTA(is_test = True) is taking large time to run I eventually interrupted it after some time. what is wrong in it ?