EDIT : even the numbers of classes in both the training and validation set are conserved : 120 classes ! get_cv_idxs() = magic function ?
Note : I used the code below to check the number of classes in both training and validation sets :
# training set
unique, counts = np.unique(data.trn_ds.y, return_counts=True)
dict(zip(unique, counts))
# validation set
unique, counts = np.unique(data.val_ds.y, return_counts=True)
dict(zip(unique, counts))
Hello,
in the dog breed competition, we use get_cv_idxs() to create randomly a validation set as following :
label_csv = f'{PATH}labels.csv'
n = len(list(open(label_csv)))-1
val_idxs = get_cv_idxs(n)
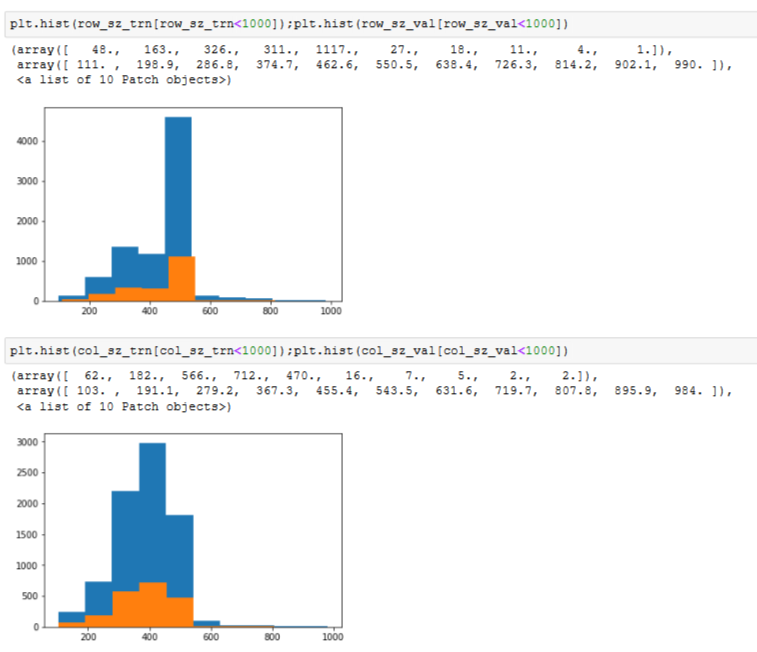
I wanted to check through histograms the similitude of our training and validation sets after data adaptation to our model through the following code :
Below the histograms for row and column sizes under 1000. I’m quite surprised by the perfect similitudes of the training and validation sets (same thing if you take all rows and columns).
Does it means using get_cv_idxs() will ALWAYS give a validation set similar to the training set or we are lucky here ?
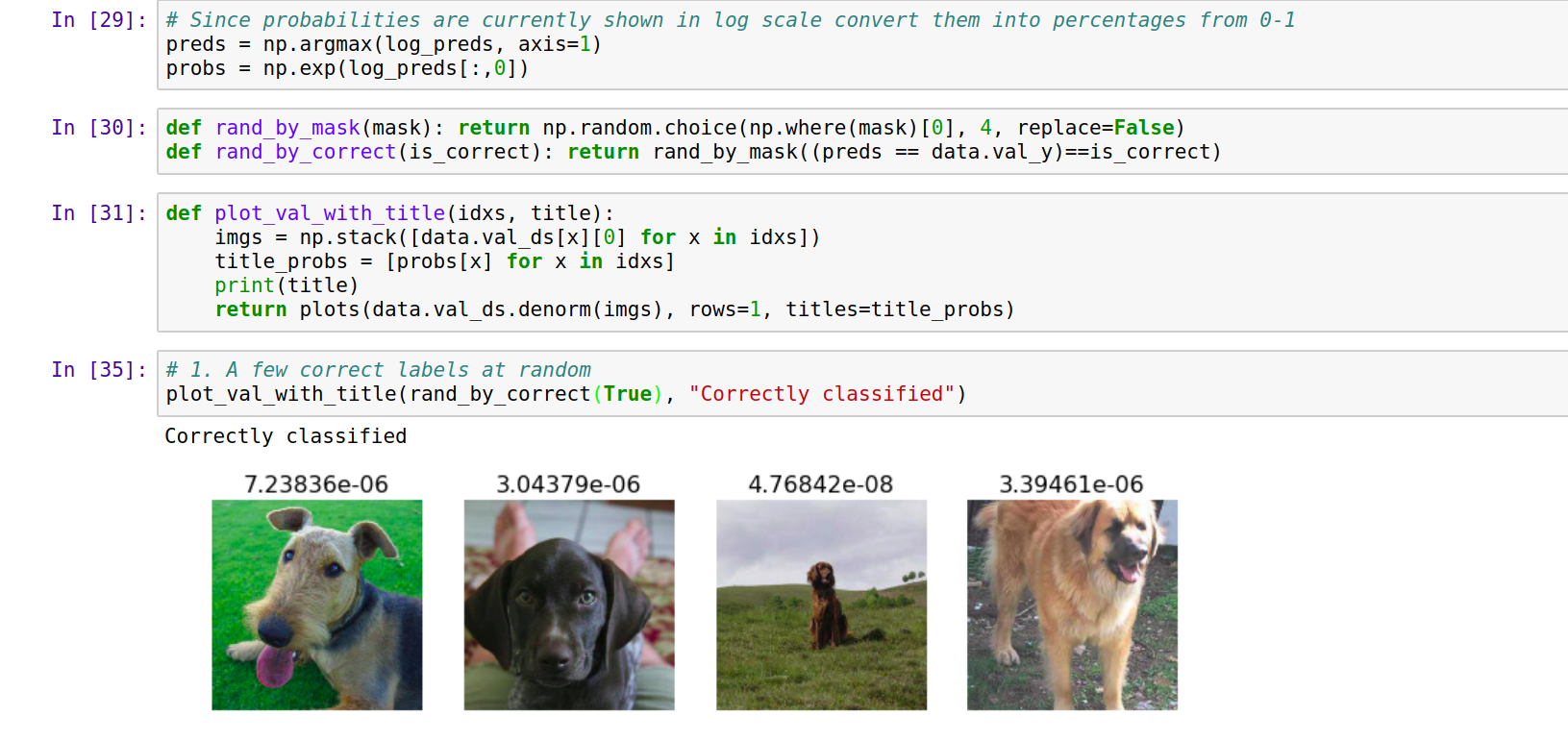
I’m getting an accuracy of 93% on the breed identification. Now I’m trying to analyze my results (using Lesson 1 lecture as an example). Arguably I know little to nothing about dog breeds – However the following are the correctly classified dog breed yet they don’t look anything alike. Am I analyzing my data correctly?
Yep they look different because your have 120 classes, not 2. To see why you have incorrectly classified you need to compare real class image with predicted class. They gonna be similar. At least in my case they were very similar.
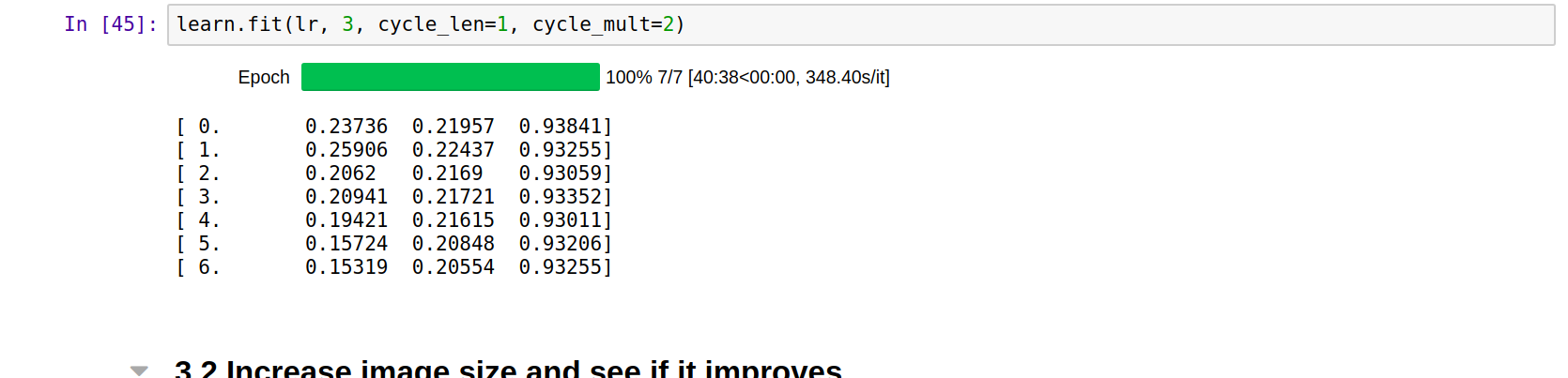
93% is probably the max what resnext_101 can do on its own.
For the appropriate models is it just pick various models until I find one with great results? So far I’ve used the models we’ve covered in class, I also used renset34. How can I go about finding models to use?
Sorry, I don`t think I have. I had 5 predictions from 5 different models and was checking manually random pics when observed 3 predictions of one class and 2 predictions of another.
When we are newbies I think thats how things work. In this specific case you can simply select a model with best accuracy on imagenet and it should have the best accuracy on dog breeds which is a subset of imagenet images.
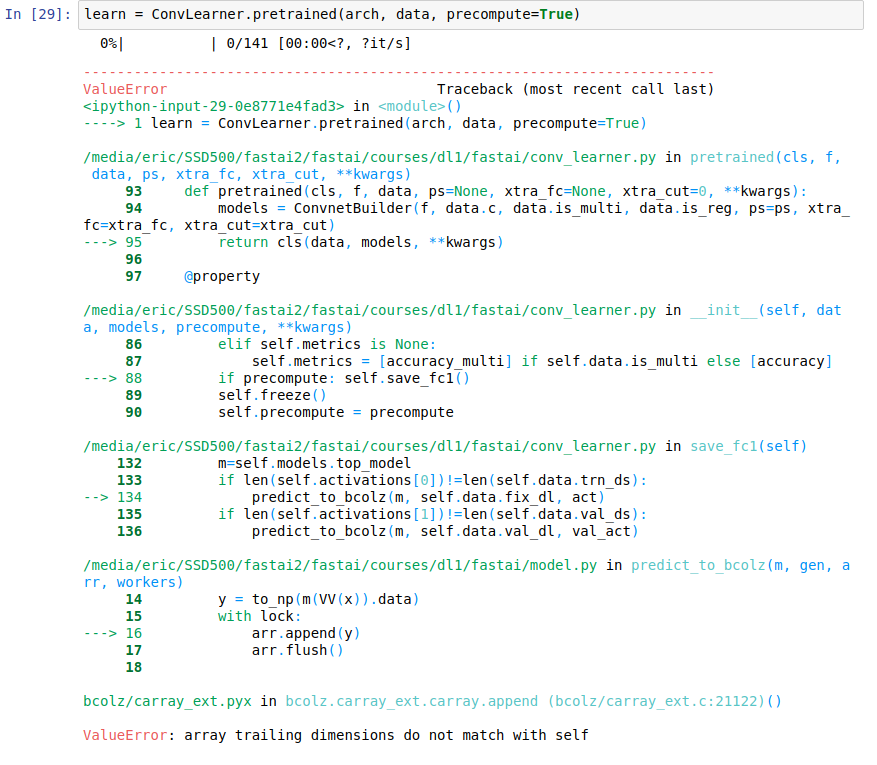
For those using Nasnet, did you encounter the following error in the “Precompute” section, when running learn = ConvLearner.pretrained(arch, data, precompute=True) ?
I’m getting a “ValueError: array trailing dimensions do not match with self” and it’s not showing up anything related on Google so far.
 Can you somehow send me a link for download ? will then modify the python code to use it.
Can you somehow send me a link for download ? will then modify the python code to use it.