A moment of glory for guys - nice feeling to be in top  . I just wonder why not absolute 0?
. I just wonder why not absolute 0?
9 hours straight on p2.xlarge with inception_4 and resent101_64 without unfreeze!
multiclass_loss:
- inception_4: 0.19768 - Position 50
- resnet101_64: worse than inception_4 - Position No improvement
- emsemble: 0.17038 - Position 29
#ensemble is bliss.
I can see many fastai students with the best of @sermakarevich with loss of 0.13987, @jamesrequa 0.15319, @thiago .15421, @rikiya .15387, @A_TF57 .15945, @lgvaz .16052, @suvash .16059, @z0k, @bushaev .16094, @rishubhkhurana .16567. Guys, apart from multiple epochs, what would you recommend to improve the score?
Thank you everyone for inspiring enough!
5 Likes
Congrats, thats nice score. Tip for score improvement - just read this thread, everything you need is already here. Both how to get < 0.14 and even how to get <0.001  .
.
2 Likes
Using completely different data-set for training?
I haven’t visited this competition in a while but I guess you could try training on entire data set (not just on 80% of it), if you haven’t done so. And create different models with different sz parameter, especially inception net. Then, ensemble them.
It simply scales it up (with linear interpolation).
To apply to one image, see How do we use our model against a specific image?
1 Like
Seems like the pretrained data for nasnet (pytorch) is not available on the servers right now, the ones defined here.
Somehow it’s been removed upstream.
Any other ways to get a hold of this file ? @sermakarevich maybe you could share the ones cached on your machine ? ( it’s downloaded to $HOME/.torch/models/nasnetalarge-dc8c1432.pth )
congrats there ! regarding the techniques, what @sermakarevich said 
I’ve only ensembled a bunch of various models. Haven’t had time for anything more.
I have the nasnet weights too if you still need them
yes please @jamesrequa !  Can you somehow send me a link for download ? will then modify the python code to use it.
Can you somehow send me a link for download ? will then modify the python code to use it.
I think the best going forward might be to upload it to files.fast.ai , and modify the nasnet.py to read from there instead. ping @jeremy
Ah. I’d opened an issue on the author’s repo and it’s back again now.
Try once again, I just checked and it worked for me.
No worries. The author just put the files back, after I mentioned it on the Github repo issue above, most likely an accident. It works now.
1 Like
Also, training Nasnet is slööööööööw !
Yep, linear regression is waaaay faster
1 Like
It’s much faster if you install the latest pytorch from source, FYI.
2 Likes
EDIT : even the numbers of classes in both the training and validation set are conserved : 120 classes !
get_cv_idxs() = magic function ? 
Note : I used the code below to check the number of classes in both training and validation sets :
# training set
unique, counts = np.unique(data.trn_ds.y, return_counts=True)
dict(zip(unique, counts))
# validation set
unique, counts = np.unique(data.val_ds.y, return_counts=True)
dict(zip(unique, counts))
Hello,
in the dog breed competition, we use get_cv_idxs() to create randomly a validation set as following :
label_csv = f'{PATH}labels.csv'
n = len(list(open(label_csv)))-1
val_idxs = get_cv_idxs(n)
I wanted to check through histograms the similitude of our training and validation sets after data adaptation to our model through the following code :
tfms = tfms_from_model(arch, sz, aug_tfms=transforms_side_on, max_zoom=1.1)
data = ImageClassifierData.from_csv(PATH, 'train', label_csv, test_name='test',
val_idxs=val_idxs, suffix='.jpg', tfms=tfms, bs=bs)
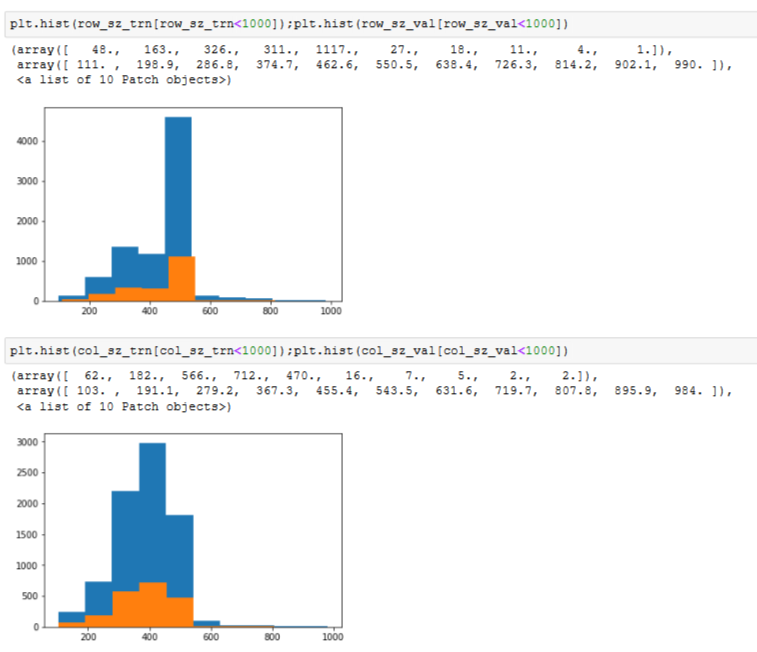
Below the histograms for row and column sizes under 1000. I’m quite surprised by the perfect similitudes of the training and validation sets (same thing if you take all rows and columns).
Does it means using get_cv_idxs() will ALWAYS give a validation set similar to the training set or we are lucky here ?
1 Like
Thank you for your answer @jeremy about small images (under sz size) that are scaled up and for the link to how to make predictions against one image.
About getting the display of a specific image to see the effects of data augmentation on it, I found to change the number num in the following code :
def get_augs():
data = ImageClassifierData.from_csv(PATH, 'train', label_csv, test_name='test',
val_idxs=val_idxs, suffix='.jpg', tfms=tfms, bs=bs)
x,_ = next(iter(data.aug_dl))
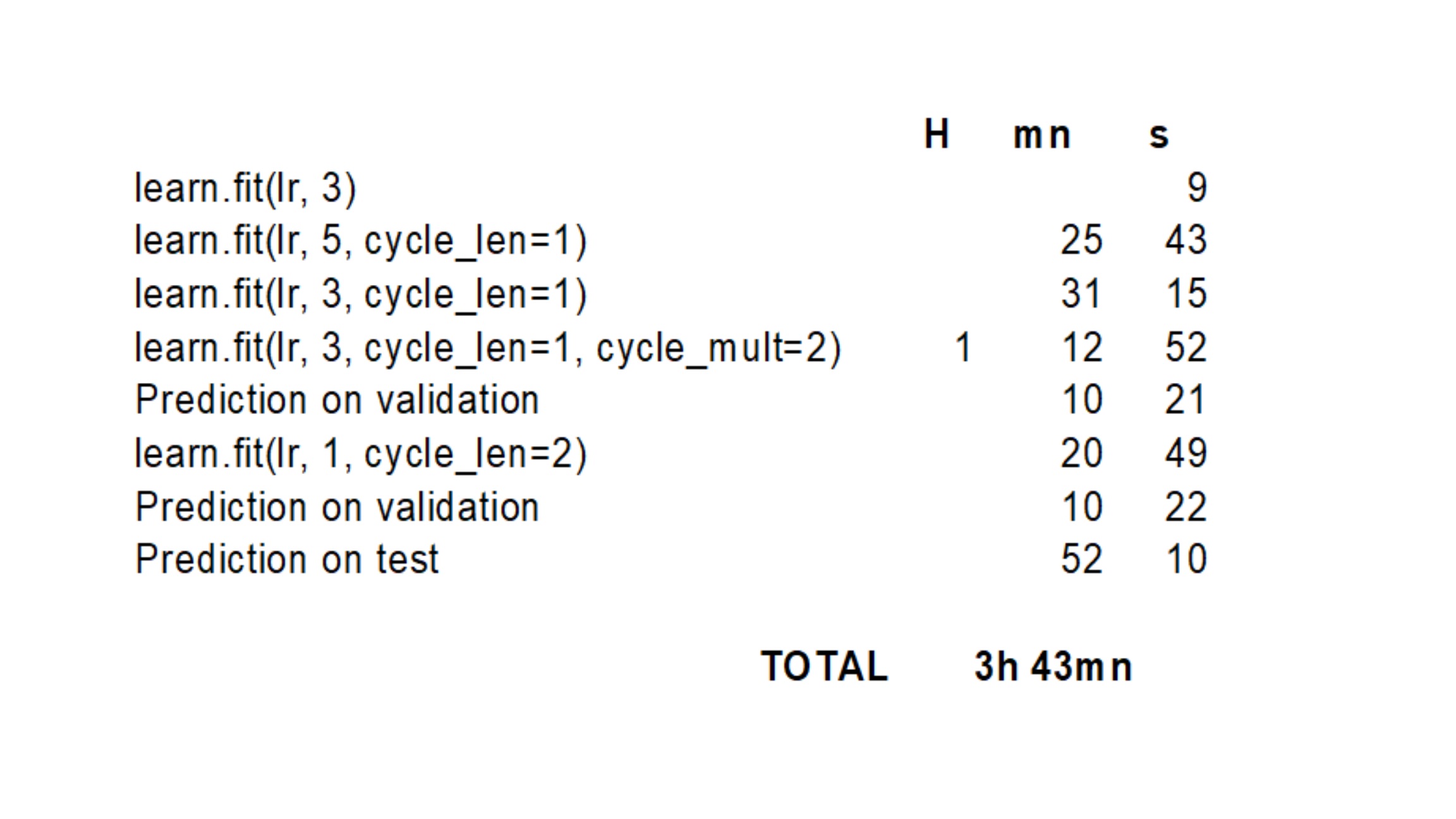
return data.trn_ds.denorm(x)[num]I would like to know what is your training + testing time on AWS (p2.xlarge) :
- for the Dog Breed competition
- with the resnext101_64 model
- learning rate = 1e-2
- validation set = 20% training set
- precompute=False but the first fit
Mine is almost 4h… (without the time for learning the lr, trials, etc.). How to reduce it ?
1 Like
I’m getting an accuracy of 93% on the breed identification. Now I’m trying to analyze my results (using Lesson 1 lecture as an example). Arguably I know little to nothing about dog breeds – However the following are the correctly classified dog breed yet they don’t look anything alike. Am I analyzing my data correctly?
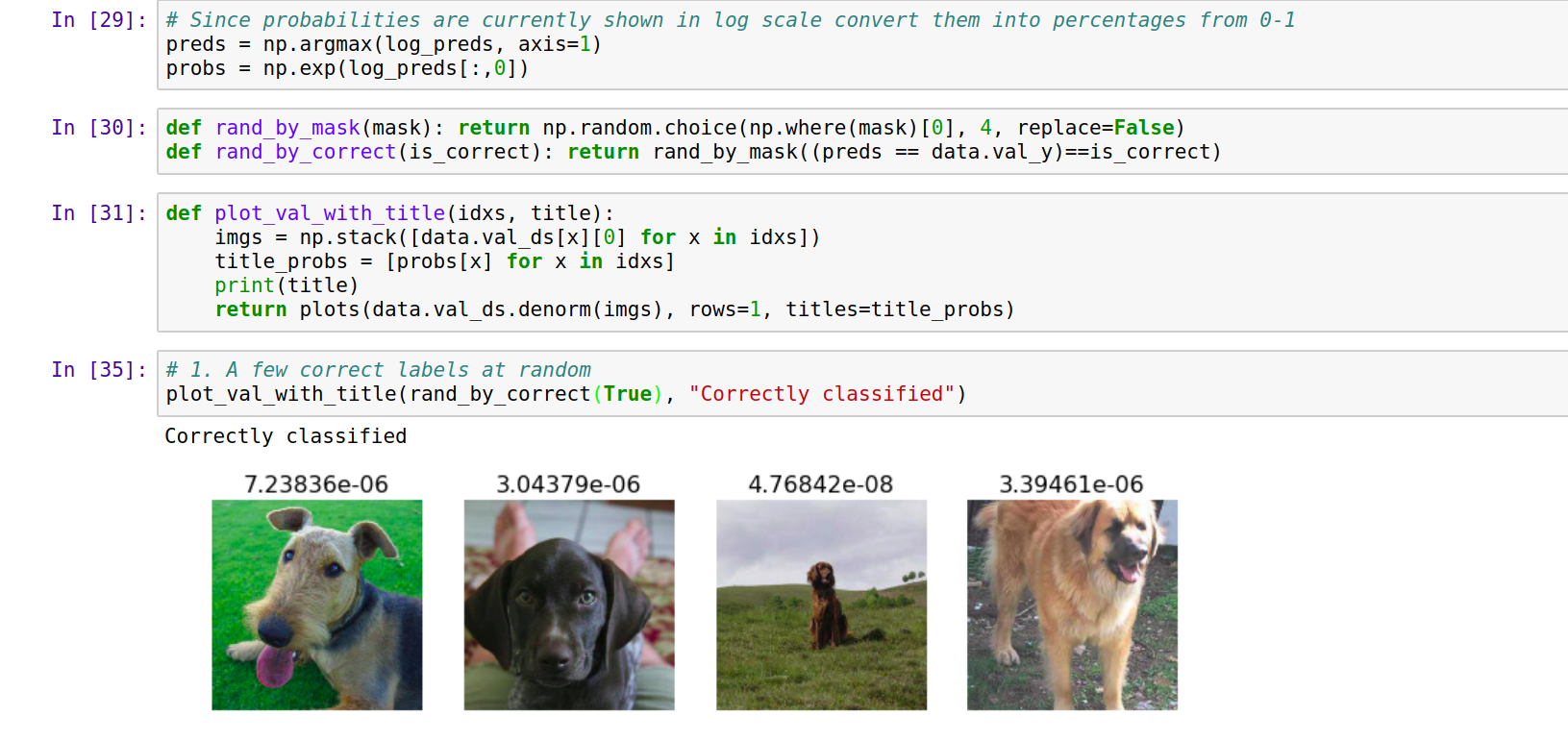
Thanks.