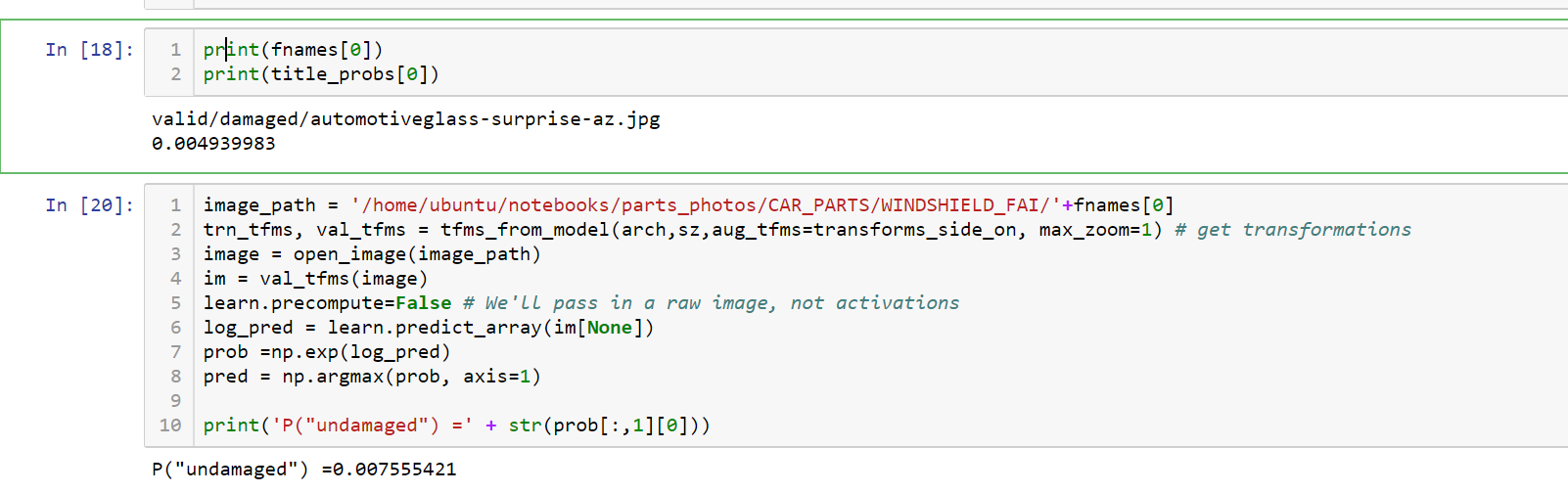
I have noticed a very strange behavior in my model. When I print the probabilities for photos from the validation set using : plot_val_with_title(rand_by_correct(True), "Correctly classified")
I get different probabilities, than when I score the exactly same pictures myself, using the following code: image_path = '/home/ubuntu/notebooks/photos/valid/group1/979794_3.jpg' trn_tfms, val_tfms = tfms_from_model(arch,sz,aug_tfms=transforms_side_on, max_zoom=1) # get transformations image = open_image(image_path) im = val_tfms(image) learn.precompute=False # We'll pass in a raw image, not activations log_pred = learn.predict_array(im[None]) prob =np.exp(log_pred) pred = np.argmax(prob, axis=1) print(pred[0])
For example one probability is equal to 0.9, and the second 0.99, or 0.74 vs 0.57.
Its all happening in one notebook, on the same model instance and using the same settings.
I’ll be very grateful for some feedback as this is totally unexpected behavior and leads to incorrect probabilities for new (out of the validation/train sets) pictures.
Interesting. Would it be possible to put your notebook with outputs that show different prediction results in gist.github.com and share here? To create a gist, drag your notebook in a new gist.github.com
Hi @MagdaG - Thanks for posting this. I think you found a fast.ai bug. Basically, when the model is in Training mode, it has Dropouts enabled. During Evaluations, dropouts are not performed. To do this, we switch the model to model.train() and model.eval().
This is taken care by Fast.ai Learner during predict and fit process. Typically we use predict_dl or TTA to predict and it’s takes care of switching the model to model.eval(). This might have been missed in predict_array method of learner.
If my hypothesis is correct, you could fix it by -