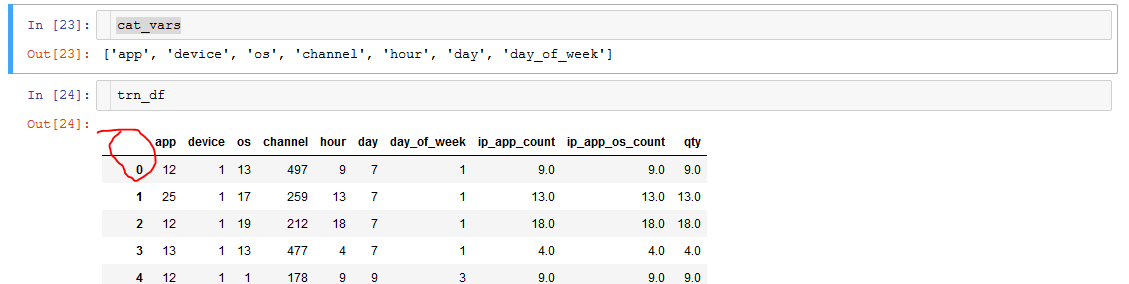
I have been spending most of today with an error I just cannot figure out.
I am trying to do binary classification on structured data and all works perfectly fine during training but when I am trying to do prediction on the test-set it falls apart with the following error:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-67-0b44351ee6aa> in <module>()
----> 1 preds = learn.predict_dl(md.test_dl)
~/projects/fastai/fastai/learner.py in predict_dl(self, dl)
266 return predict_with_targs(self.model, dl)
267
--> 268 def predict_dl(self, dl): return predict_with_targs(self.model, dl)[0]
269
270 def predict_array(self, arr):
~/projects/fastai/fastai/model.py in predict_with_targs(m, dl)
150
151 def predict_with_targs(m, dl):
--> 152 preda,targa = predict_with_targs_(m, dl)
153 return to_np(torch.cat(preda)), to_np(torch.cat(targa))
154
~/projects/fastai/fastai/model.py in predict_with_targs_(m, dl)
146 if hasattr(m, 'reset'): m.reset()
147 res = []
--> 148 for *x,y in iter(dl): res.append([get_prediction(m(*VV(x))),y])
149 return zip(*res)
150
~/anaconda2/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
355 result = self._slow_forward(*input, **kwargs)
356 else:
--> 357 result = self.forward(*input, **kwargs)
358 for hook in self._forward_hooks.values():
359 hook_result = hook(self, input, result)
<ipython-input-53-895619868d8b> in forward(self, x_cat, x_cont)
34 if self.use_bn: x = b(x)
35 x = d(x)
---> 36 x = self.outp(x)
37 if self.y_range:
38 x = F.sigmoid(x)
~/anaconda2/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
355 result = self._slow_forward(*input, **kwargs)
356 else:
--> 357 result = self.forward(*input, **kwargs)
358 for hook in self._forward_hooks.values():
359 hook_result = hook(self, input, result)
~/anaconda2/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/linear.py in forward(self, input)
53
54 def forward(self, input):
---> 55 return F.linear(input, self.weight, self.bias)
56
57 def __repr__(self):
~/anaconda2/envs/fastai/lib/python3.6/site-packages/torch/nn/functional.py in linear(input, weight, bias)
833 if input.dim() == 2 and bias is not None:
834 # fused op is marginally faster
--> 835 return torch.addmm(bias, input, weight.t())
836
837 output = input.matmul(weight.t())
RuntimeError: cuda runtime error (59) : device-side assert triggered at /opt/conda/conda-bld/pytorch_1518244421288/work/torch/lib/THC/THCTensorCopy.cu:204
The code I am trying to run is this:
model = MixedInputModel(emb_szs, n_cont=0, emb_drop=0, out_sz=2, szs=[500], drops=[0.5]).cuda()
bm = BasicModel(model, 'binary_classifier')
trn_df, trn_y = df.iloc[:train_size], y[:train_size]
val_df, val_y = df.iloc[train_size:], y[train_size:]
md = ColumnarModelData.from_data_frames(DIR_ROOT, trn_df, val_df, trn_y.astype('int'), val_y.astype('int'), cat_vars, 128, test_df=df_test)
learn = StructuredLearner(md, bm)
learn.crit = F.cross_entropy
The basic idea is from : https://github.com/KeremTurgutlu/deeplearning/blob/master/avazu/FAST.AI%20Classification%20-%20Kaggle%20Avazu%20CTR.ipynb
But I get the another error if I instead use the fast.ai out-of-box code and run (similar to the Rossman notebook):
m = md.get_learner(emb_szs, len(df.columns) - len(cat_vars), 0.5, 1, [1000,500], [0.001,0.01], y_range=y_range)
m.crit = F.binary_cross_entropy
pred_test=m.predict(False)
In this case I get:
RuntimeError: cuda runtime error (59) : device-side assert triggered at /opt/conda/conda-bld/pytorch_1518244421288/work/torch/lib/THCUNN/generic/Threshold.cu:34
So. No matter what I do it seems my test-set predictions are crashing.
This is how the data frames look like:
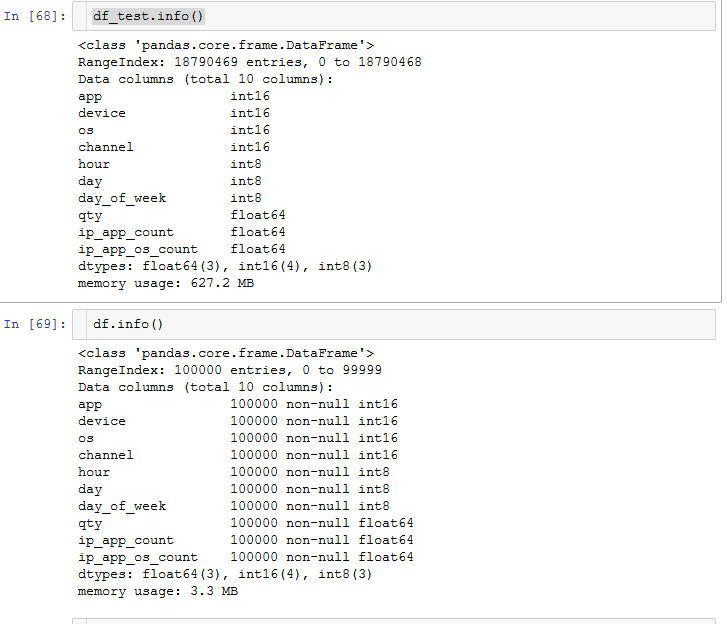
Anyone have any idea about what to do?