I had a very similar experience… In general seems that IO is a major, major area to figure out - I have been having issues across multiple projects to the point where I started doing some research and writing a monster post on it (it’s still in the works).
FYI I’ve been having RAM issues for my NLP work recently, so have started using the chunklen param in pandas when reading the CSV, to process it a chunk at a time. It adds complexity and code, but it’s a good approach for large datasets.
Pandas also have a nice parameter ‘downcast’ for numeric types eg. pd.to_numeric(series, downcast=‘float’) When downcasted the resulting data to the smallest numerical dtype possible. As explained in the docs it follows below rules:
‘integer’ or ‘signed’: smallest signed int dtype (min.: np.int8)
‘unsigned’: smallest unsigned int dtype (min.: np.uint8)
You mentioned in one of the videos that you would post your Fastai notebook for Favorita, AFTER the competition ends, due to regulations and ethics for Kaggle rules
Any chance you could do so ?
There might be more than my humble self looking for it, especially how you went from training (I think I got that right) to predicting/submitting (I failed that part with Fastai library).
@EricPB, if you would have this already on your computer and it wouldn’t be too much of a problem, would you be so kind and check these two things?
I am thinking that output from model.summary() might also provide some insights.
I was planning to implement @Lingzhi’s model and looked at the code for quite a while where I now think I understand what it does. Am caught up with a lot of other things ATM and the 2nd part of the course is just around the corner… (still crossing my fingers I’ll get in ).
The cool thing with this kernel is that we could literally copy the code to line 232 and this should give us the dataset… should be a great starting point for messing around with this.
I have no clue why the first layer is an LSTM nor what it does. I do not think his statement in the comments is correct that it is equivalent to a Dense layer.
It’s really cool though. Could it be that the remember / forget gates are still learned? Sort of like we are using the LSTM cell to take a look at the data and keep only the parts that are important?
Well, this is crazy. Don’t think I will be able to wrap my head around this as I don’t want to explore that keras layer further.
One way to find out would be rerunning the training with the Dense layer instead.
Either way, this is really helpful Thanks a lot @EricPB! I also find the part where the 561 vector is being fed into the model quite mind boggling. Intuitively feeding it something of shape [type_of_data x days_in_train] makes more sense. For instance, I think Lighzi stacked a vector of unit_sales and a vector of promo_days and some statistics I think to form something of dimensionality [3 x days_in_train]
I’m working (or my PC is ) on a lighter/faster version, with less epochs per step (15 max, so Callbacks probably can’t kick in), to experiment with different parameters, including the “why choose LSTM over Dense in the first layer”.
I’ll post a revised Jupyter Notebook on GitHub so everyone can experiment as well.
But:
As it is, you’ll still need at least 50Gb RAM to run it, due to the “Preparing Dataset” cells #24 to #27.
On my rig, this is not a big issue because I have 32Gb “real” RAM and allocated 140Gb “SWAP File” from the 1Tb Samsung 960 NVMe, so it’s rather painless. But if you don’t have a SWAP helping, the notebook may crash.
The whole kernel is without any comment, so expect some reverse-engineering work to figure out what is done by each cell.
The current open question for me: why did he choose to run 16 networks -or steps- ? Is it related to the duration of the Test set (ie 16 days) ? If I were to use his template for another project with a Test set of 25 days, should I need 25 networks ? Or just a coincidence ?
Errr… I’m pretty sure if you asked in the comments section on Kaggle, or on KaggleNoobs, someone will find the original culprit and get you an answer.
This is my humble opinion but I agree with it.
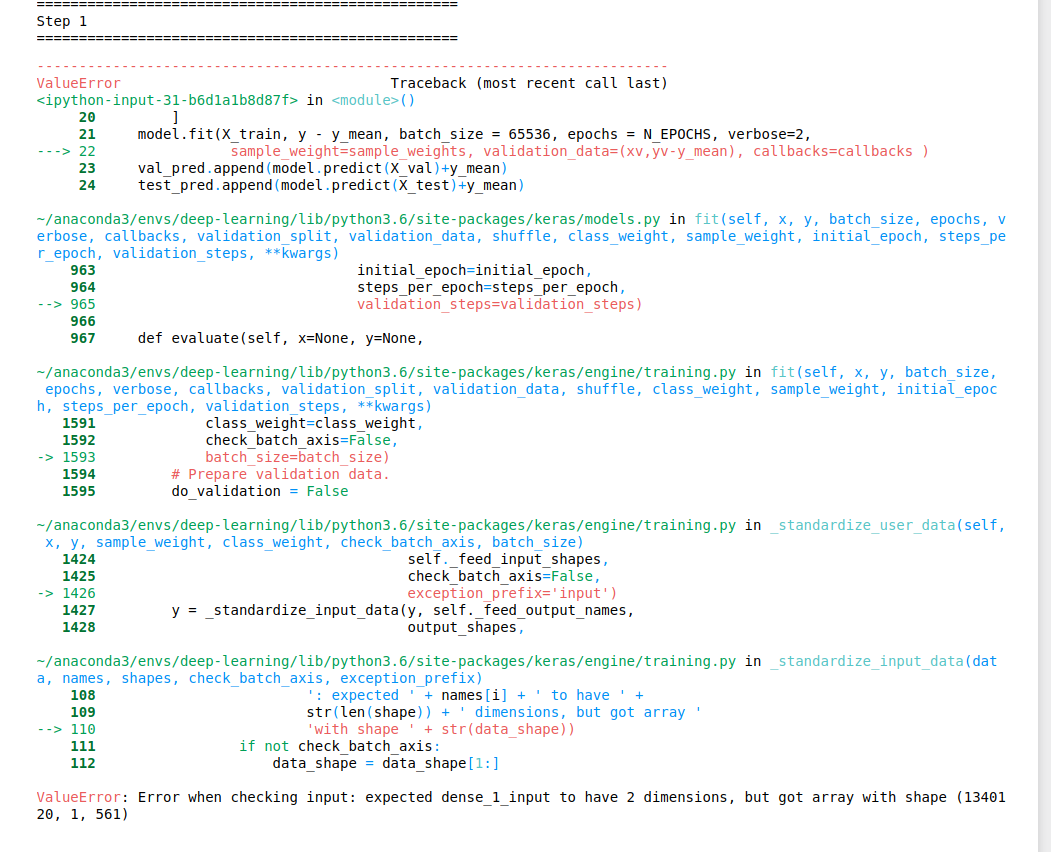
This kernel is based on senkin13’s kernel: https://www.kaggle.com/senkin13/lstm-starter. You can replace model.add(LSTM(512, input_shape=(X_train.shape[1],X_train.shape[2]))) with model.add(Dense(512, input_dim=X_train.shape[1])), I think there is no difference.
Generates the following error (I didn’t try to investigate, just pasted it and run the code).
Thanks a lot for your help @s.s.o but it didn’t work (not you to blame, just my noobish debugging skills).
It’s pretty late in Stockholm now, maybe 02:00, so I’ll give it a try again tomorrow.
In any case, the basic Jupyter Notebook should be working fine so I’ll try and post it on GitHub,
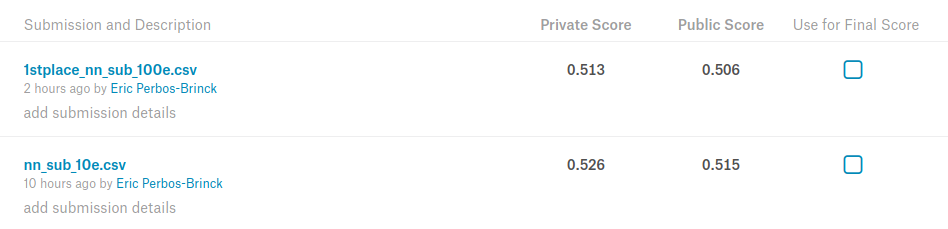
Here’s an edited Jupyter Notebook for the 1st place solution.
This version, running on 15 epochs per set, 40sec per epoch on 1080Ti, scores 0.519 on the Private LB to get a Silver Medal.
With @radek’s comment, I got the “But of course !” moment about the 16 networks, each one dedicated to forecasting a single day of the 16 days in Test
Another thing I found very neat is his careful choice of validation dates: he didn’t go for the last 16 days before the Test starting date (2017-8-16) , bluntly that should be 2017-7-31 -> 8-15.
He chose instead the latest 16 days’ Train bracket which most resembled the 16 days’ Test, that is 2017-7-26 -> 8-9.
Doing so, he made sure the two sets had the same number of respective weekdays (like 3 medium sales volume Wednesdays/Thursdays, vs 3 low volume Mondays/Tuesdays.) + it fully captured the end-of-month week-end where payroll is about to drop but is a banking holiday for payment with credit/Visa cards, so people won’t be charged until next Monday (a validation starting on Monday July 31 would miss the boost of previous final friday/saturday of July).
 (it’s still in the works).
(it’s still in the works). I upgraded to 64 GB.
I upgraded to 64 GB.
 ) on a lighter/faster version, with less epochs per step (15 max, so Callbacks probably can’t kick in), to experiment with different parameters, including the “why choose LSTM over Dense in the first layer”.
) on a lighter/faster version, with less epochs per step (15 max, so Callbacks probably can’t kick in), to experiment with different parameters, including the “why choose LSTM over Dense in the first layer”.