I want to train a dataset of black and white (no greyscale either) images, I recall that on lesson 2, Jeremy said that he had to change something on vgg16() when he did the lung cancer dataset. Should I see any benefit if I change it? And if yes, what do I have to change in the model?
2 Likes
Easiest solution is to repeat your grayscale data x3 along the channel axis. You could weight that differently for the different channels or if you’re adventurous try to stick a 3 filter convolutional layer that you train between the grayscale data and the pretrained model (make sure the pretrained weights are frozen before training).
Alternatively you can take the sum of the weights of the first convolutional layer kernel along the input channel axis and create a new model that expects one channel input and load those weights into the first layer. This will reduce the number of operations you perform.
7 Likes
Thanks, I guess I might need to finish the lessons first (Im viewing lesson 2 at the moment) because I cant understand most of what you said.
Let us know if it still doesn’t make sense after you’ve finished part 1 - @davecg’s advice is exactly right 
4 Likes
Hi, I still dont understand. If I change model.add(Lambda(vgg_preprocess, input_shape=(3,224,224), output_shape=(3,224,224))) to model.add(Lambda(vgg_preprocess, input_shape=(1,224,224), output_shape=(1,224,224))) it gives me an error. Im using vgg16.py and training all layers with no weights loading by the way. I also really need to do this because I’m gonna end using a 550x500 image resize and when I tried with (3,550,550) it would use all my memory and crash.
I think I also need to change this lines but I dont know how:
vgg_mean = np.array([128, 128, 128], dtype=np.float32).reshape((3,1,1))
def vgg_preprocess(x):
x = x - vgg_mean
return x[:, ::-1] # reverse axis rgb->bgr
Help please…
I’m curious about the second method you have mentioned.
But i don’t understand what do you mean " take the sum of the weights of the first convolutional layer kernel along the input channel axis and create a new model that expects one channel input and load those weights into the first layer."
Could you give me an example code?
Thanks a lot!!!
For a kxk kernel with 3 input channels (RGB) and N output channels, your weights are a 3 x k x k x N array (dimension order depends on library).
If you sum your array along the first axis - I.e a.sum(axis=0), your new weights (expand to 1 x k x k x N) would give you the exact same output for a grayscale image as the original weights would for a grayscale image repeated across three channels.
Easiest way to do this for Keras for me was to edit the hdf5 model file directly. Wrote some code for it but there have been a few API changes since.
1 Like
For ct scan images, depending on the problem to focus, it could be interesting to try to rescale the linear HU values to different anatomical perceptual windowing (W/H) per channel. For example :
Raw Greyscale pixels => HU from -1000 to 3000
Rescale to 3 channels data :
1st channel (body window) => -150 to 250
2nd channel (lung window) => -1000 to 500
3rd channel (bone window) => -700 to 2300
The convolutional layers could potentiallty extract, more precisely, different complementary useful features for each channel and still use the 3 channels RGB pretrained weights from natural imagenet images. This is basically some kind of pixel feature engineering in the traditional machine learning terminology, but this engineering makes sense from an anatomic, pathologic and perceptual perspective.
2 Likes
All of that information is still contained within the initial grayscale data though, so if that kind of windowing is valuable to the model it should learn it. The pseudo color wouldn’t add new information.
ImageNet is also trained on natural images, and when I’ve created pseudocolor images like this they tend to look a little weird.
Also, I know there’s a huge body of research on this that I’ve barely looked into, but isn’t the whole window/level issue more about the limitations of computer monitors and the human eye? A convolutional layer can easily distinguish between 600 and 1000 Hounsfield units even if I can’t on lung windows.
I haven’t tested it thoroughly, but my bet is that it’s better to let the model learn from the raw grayscale data as a single channel.
Of course mixing different ct windowing in RGB channels will look weird for the human eye but that doesn’t mean it isn’t useful from a machine perspective.
You are right that the same information is contained in the initial grayscale data. But the goal of this idea is simply to scale and average the important data in different channels to fully use the 3-channels pretrained weights; the same scaling is done with RGB images and color continous wavelength when you take a digital photography. As we know, scaling and averaging the data helps in DL for different reasons : improving the SGD convergence and getting more precise numerical calculation for the same amount of bits used. I’ll probably try the idea with some classification problem in cerebral ct scans. I’ll let you know of the results if you are interested.
1 Like
For the first week assigment I am trying to do the Facial Expression Recognition Challenge (https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge)
However, I have some problems using VGG16 to grayscale images.
I am using keras 2.0.2 with Tensorflow 1.0.1. I am using directly the keras.application module.
Here is my code.
from keras.applications.vgg16 import VGG16
from keras_tqdm import TQDMNotebookCallback
from keras.preprocessing import image
from keras.layers import Dense, Dropout, Flatten
from keras.models import Sequential, Model
def get_batches(path, gen=image.ImageDataGenerator(rescale=1./255.), shuffle=True, batch_size=batch_size, class_mode='categorical'):
"""
Takes the path to a directory, and generates batches of augmented/normalized data. Yields batches indefinitely, in an infinite loop.
See Keras documentation: https://keras.io/preprocessing/image/
"""
global target_size
return gen.flow_from_directory(path, target_size=target_size,
class_mode=class_mode, shuffle=shuffle, batch_size=batch_size)
#Set constants. You can experiment with no_of_epochs to improve the model
target_size = (48,48)
batch_size=32
no_of_epochs=3
vgg = VGG16(include_top=False, input_shape=(*target_size, 3))
input_layer = vgg.input
for l in vgg.layers:
l.trainable = False
x = vgg.layers[-1].output
x = Flatten()(x)
x = Dense(1000, activation='relu')(x)
x = Dense(7, activation='softmax')(x)
model = Model(inputs=input_layer, outputs=x)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
I am reusing the get_batches provided in Vgg16 class with additionally addion rescale=1./255. (As suggested here https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html , I also tried without it)
After fitting the model is not learning anything. Here are my 15 epochs:
{'acc': [0.138671875,
0.1474609375,
0.150390625,
0.1240234375,
0.1318359375,
0.140625,
0.13671875,
0.13671875,
0.14844533602297008,
0.14453125,
0.15234375,
0.158203125,
0.1435546875,
0.1376953125,
0.140625],
'loss': [13.882968783378601,
13.741306006908417,
13.69408506155014,
14.119073778390884,
13.993151187896729,
13.851488202810287,
13.914449602365494,
13.914449572563171,
13.725439321313244,
13.788526982069016,
13.66260439157486,
13.56816229224205,
13.804267376661301,
13.898709148168564,
13.851488292217255],
'val_acc': [0.12385434729128095,
0.13021618904346435,
0.13723061679834064,
0.12831310378994304,
0.12806539509905898,
0.1293039385719349,
0.13252415160141223,
0.12707456032075828,
0.13277186029598742,
0.13425811245974734,
0.12509289076415683,
0.13574660633484162,
0.13301956899056258,
0.1317810255176867,
0.13079019073938597],
'val_loss': [14.121799071885762,
14.019258416436196,
13.906199178395662,
14.049932523797814,
14.053925060180559,
14.033962043524085,
13.982058439096484,
14.069895437220284,
13.978065769241859,
13.954110261559457,
14.101836206418676,
13.93011857805209,
13.974073174981926,
13.994036282352035,
14.0100066745107]}
I cannot really see what I am doing wrong here. Any ideas?
Thanks.
@ale and @davecg One of the other techniques that we found useful is mentioned in the lectures with ‘learning colorspace transformations’ (https://youtu.be/bZmJvmxfH6I?t=13m41s) where you basically prepend your model with a 1x1 convolution with a depth of 10 followed by a 1x1 convolution with a depth of 3. This might be combined well with the pseudocolor idea of @alexandrecc
We also combined it with batch normalization which improved the training time for the conv2d layers. I added the keras code below to make
model = Sequential()
model.add(in_model)
model.add(BatchNormalization())
model.add(Conv2D(10, kernel_size = (1,1), padding = 'same', activation = 'relu'))
model.add(Conv2D(3, kernel_size = (1,1), padding = 'same', activation = 'relu'))
model.add(pretrained_vgg_model)
Since just descriptions and code are boring, here is an example from two slices of a CT image
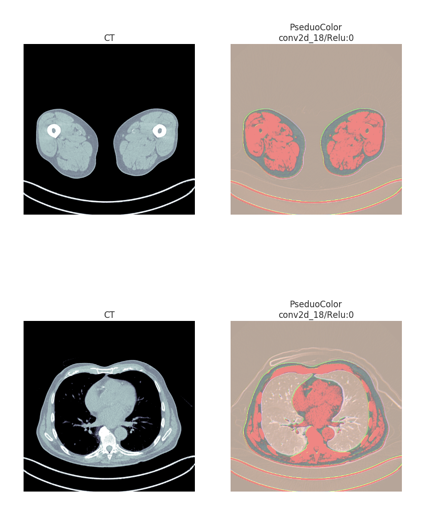
9 Likes
Hi @orbel, I am working on the same dataset. I managed to train a cnn from scratch, but I want to use Vgg16 and fine-tune to see if the results are improving. Did you manage to work with vgg and this dataset? Thanks!
Hi @kmader, thank you for sharing this!
I am wondering what “model.add(in_model)” means? I want to use Vgg16 to fine-tune a grayscale dataset, and I know it needs to preprocess the images, to subtract the mean of each channel of the imagenet data and reverse the order of RGB->BGR. Should this stept be included in “model.add(pretrained_vgg_model)”, if I am correct? The previous 2 layers will return 3 channels? Should the depths, 10 and 3, be fixed values? Hope I am not asking too much.
Kind regards.
Hi @nadia,
These are good points and indeed open to experimentation. The preprocessing step you need for the black and white images is probably just something to rescale them to 0 to 1 or -1 to 1 (I often just normalize them, ie subtract the mean and then divide by the standard deviation).
The layers then (ideally) learn how to transform the grayscale input into something that the pretrained model could do something with. You could try and hard-code their initial weights to be more like the preprocessing done for a VGG/Inception, but probably it is best to use random initializations.
The last layer needs to have a depth of 3 (so it fits into the input of the ImageNet trained model), but the 10 (or anything before) is entirely up to you and you should definitely try experimenting once you have a reliable cross-validation technique setup. I have also found that for some types of data batchnormalization in this preprocessing step can be useful. Also I typically lock the weights (pretrained_vgg_model.trainable = False) of the pretrained model while doing the initial training of the preprocessing layers.
Hopefully this clears things up a bit?
Kevin
Hi Kevin (@kmader), thank you for the response, it sure clears things up
I am in doubt and try to understand the following: after normalizing the grayscale images before feding them to the 2 Conv2D layers, should I substract the mean [123.68, 116.779, 103.939] and change RGB to BGR (the method that the original network VGG uses)? Or the pseudocolor images created wouldn’t allow me that?
Kind regards,
Nadia.
Hi,
I would like to train images Fashion MNIST dataset (grayscale images of 2828) on VGG-16 but it take input of 224224. However, I can not use “flow_from_directory()” function as I am accessing dataset from load_images() from keras (i.e. I have not downloaded data in my hard drive, I am directly accessing it through library keras).
Could you please provide a method/alternative to solve this problem?
Thanks,
Jyoti
You mean something like this?
Or you can google for examples that has these lines:train_generator = train_datagen.flow_from_directory(
train_data_dir, color_mode=‘grayscale’,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode=‘binary’)