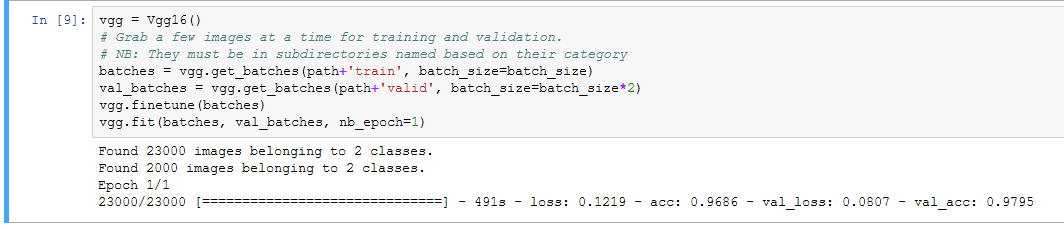
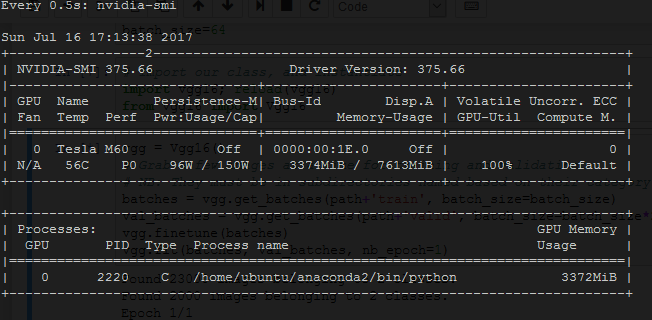
Released couple days ago AWS g3.4xlarge instances based on Nvidia Tesla M60.
They have 16CPU and 122Gb RAM at cost of 1.14$/hour on demand.
g3 looks to be much faster than g2 generation.
They are slightly better than p2 instances on Cats and Dogs model, but from performance/price perspective - p2’s are still more suitable for DL.
I can confirm this result. Quick benchmarking from my end -
Each epoch in lesson 1 was taking around 588 seconds on P2 & 460 seconds on g3.4x large. 22% increase.
Each epoch in lesson 2 was taking around 605 seconds on P2 & 456 seconds on g3.4x large. 25% increase.