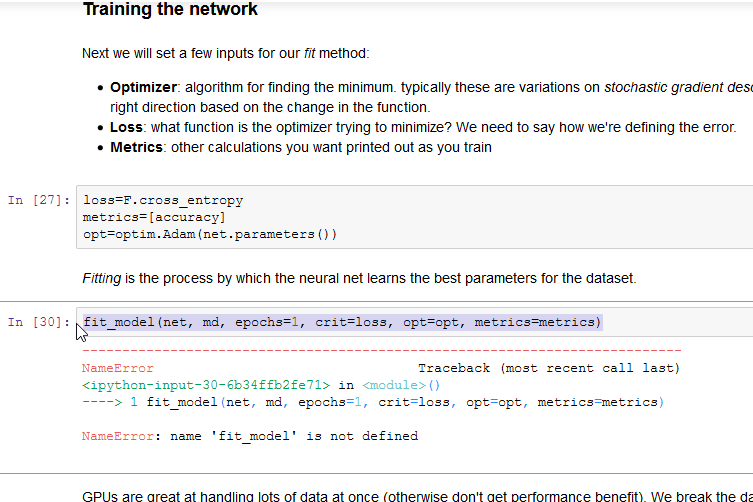
I was going through ML Lesson 1 - ml1/linalg_pytorch.ipynb
I could not find fit_model method anywhere in the fastai repo/lib.
All imports were done. Same issue on Crestle and AWS custom box.
Does anybody knows where to look for this method?
I was going through ML Lesson 1 - ml1/linalg_pytorch.ipynb
I could not find fit_model method anywhere in the fastai repo/lib.
All imports were done. Same issue on Crestle and AWS custom box.
Does anybody knows where to look for this method?
That’s not lesson 1 - that’s from the computational linear algebra course. You want lesson1-rf.ipynb
Ah, got it. Thanks.
It depends how much time you have. If you have the time, doing both will help, since the two courses support each other. But that’s a lot of work (~20 hours/week I’d guess), so if you don’t have that amount of time, focus on the DL course. You could always watch the first couple of ML videos and see whether you find them useful.
@jeremy but for the sake of curiosity from which package fit_model method should come from in linalg_pytorch.ipynb?
Hi Jeremy -
Thanks for the ML Videos. Really liked the way you sampled RF and patched the SKLearn RF code to make it possible. It’s also a lesson in reading source code and make it work for us. Open Source FTW.
I see that BaggedTrees and IsolationForest models of SKLearn has a parameter called max_samples that does similar thing by sampling only a subset of rows for each trees. Hopefully it’s only a pull request away to update RF 
Good eye @Ramesh! Maybe you could try to create that PR?.. 
(If you do - be sure to think about how to best handle OOB samples. They probably should be of size <= the sample size)
Thanks @jeremy - I am going to give it a try. Will update here once I have something to share. Thanks again for everything you do and share on ML and DL.
Hi Jeremy - Looking at XGBoost, it has a parameter called subsample (https://github.com/dmlc/xgboost/blob/master/doc/parameter.md). Does XGBoost use same subsampled data for all the trees or does it bootstrap data like RF for each tree? It’s not directly relevant to the ML lesson. I could also wait till you cover GBM and XGBoost in ML.
I’ll add sklearn_pandas and graphviz to the preinstalled libraries on Crestle.
@anurag I continue to get Nvidia graphic card error even though my GPU service was on. Any insight on this?
Sure… I’ll do that. Thanks!
I’ll add sklearn_pandas and graphviz to the preinstalled libraries on Crestle.
This is done.
@anurag, I guess I had signed up for the Crestle before fast.ai repository started loading by default. Is there a way one can get courses folder now?
Just git clone it.
Xgboost “subsample” doesn’t bootstrap rows. It randomly subsamples them, for each tree. So its more a proxy for original implementation of random forest (if you set subsample value to 0.632). In practise it gives quite comparable results.
(note that you should also modify other parameters, number of parallel trees, nrounds, eta… to get that random fore-ish xgboost ).
Nice to follow and informative,
About number of trees, maybe of interest this paper here (main insights, more than 128 trees is pointlesss for many datasets and, also from optimal -small- number of trees, DOUBLING number of trees only gives marginal small accuracy improvements. I always have this paper in mind, the link here: https://www.researchgate.net/publication/230766603_How_Many_Trees_in_a_Random_Forest
Only thing that left me scraching my head, the assesment that recent discoveries lead to use weaker trees, as it contradicts Breiman an also my -very limited- experience when doing Bayesian optimization of RF trees (weakest options are never selected, maybe not enough trees anyway). My intuition is that that particular point will strongly depend on the noise of the dataset, I will keep it in mind hopefully to draw conclusions in the future, when I am (even) older. 
Once again, thanks a lot Jeremy sharing this!
Take a look at ‘Extremely Randomized Trees’ paper for an example of what I mean.
Thanks Jeremy. I guess what you are referring to is cloning fast.ai repository. I did the same.
Actual benefit of preloaded files on crestle is that user didn’t need to download, unzip and move data manually. It took around 20-30 minutes for doing so hence this query.