I didn’t quite understand what these confidence interval from lesson 3 were about. What exactly are we looking for with this? What am I supposed to understand or to “catch” when I look at those two graphs?
Thanks
I didn’t quite understand what these confidence interval from lesson 3 were about. What exactly are we looking for with this? What am I supposed to understand or to “catch” when I look at those two graphs?
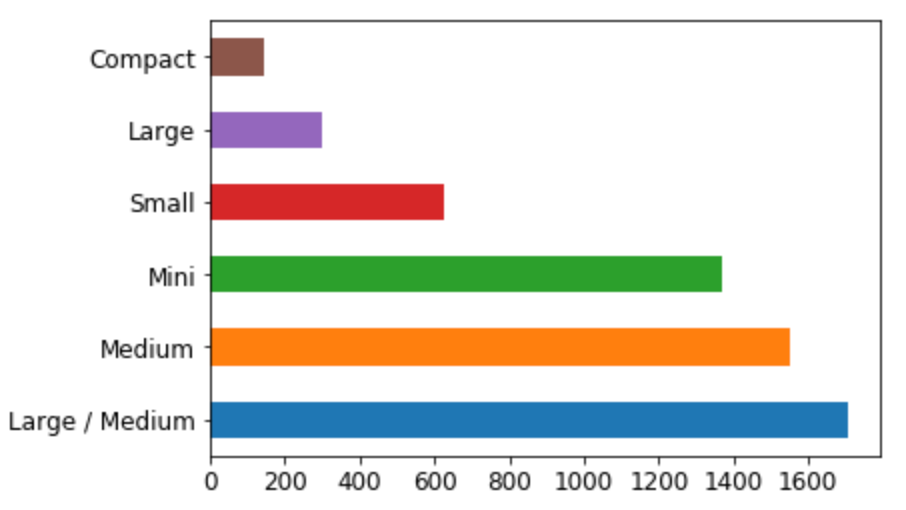
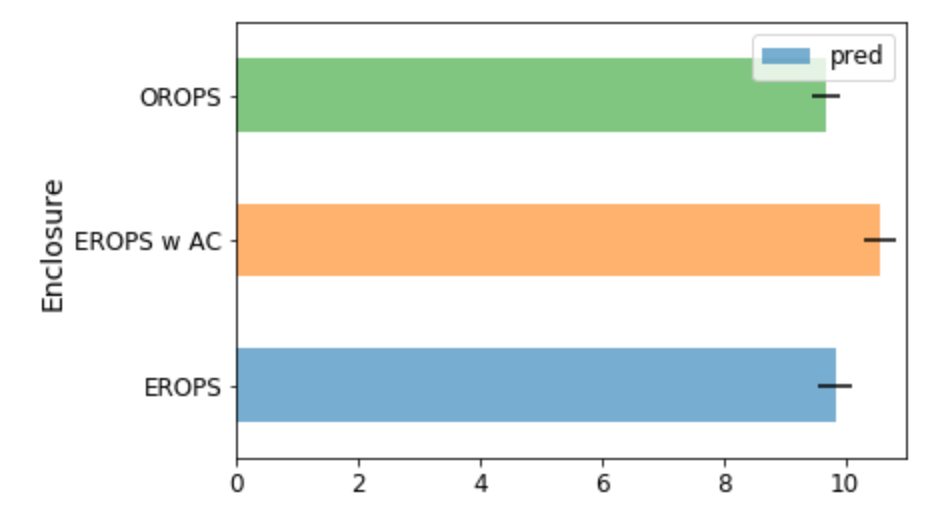
There is nothing on the first chart as there are no confidence intervals. These small horizontal lines at the end of each bar show possible distribution of predicted values by different trees. If the line is short - you have good confidence in predicted value. If the line is long its like alarm alarm you have poor predictions for this category.
I still don’t get it sorry. At which point do we consider this line to be “wide”? And lets consider it is effectively wide on say, OROPS, what can we do about it? Should we just throw away this category?
As I understood these confidence intervals serve well for business insights. Bar on the chart is average of predictions from multiple trees. Sometimes these predictions are lower, sometimes they are higher than average. Confidence interval shows how much your estimation might vary for different trees. In credit score example bank might decide to not allow credit if credit score of a client is positive but confidence interval shows for some % of cases it can be negative.
For modelling purposes it might show categories where your predictions vary significantly. Significantly for me means higher % of variation compared to average per this category to variation of predictions for other categories.
Are random forests just a way of partitioning very high dimensional space? All that happens is we pick some value from one of the dimensions and cut the entire space in half, coloring it with the mean of one group and the other half with the mean of the other group? And then we go on splitting to refine the partitioning?
That’s what a single tree would do - a forest just combines the colorings from each tree (space of whatever number dimensions) in some way, possibly via taking the mean?
Is there really all there is to this or could I completely be missing something?
Accidentally discovered how to quote from other threads so moving the discussion over to here 
I only finished watching lesson 2 but I think what @Ekami wanted to know - what are the reasons we remove some of the columns / data in lesson 3? As it is not because we inherently have something against having that many dimensions, why do we do it?
In proc_df signature we set multiple default values to None
def proc_df(df, y_fld, skip_flds=None, do_scale=False, na_dict=None,
preproc_fn=None, max_n_cat=None, subset=None):
and subsequently we mutate them if they are not set:
if na_dict is None: na_dict = {}
Is there a particular reason for this? It might be for nicer function signature but wondering if there is any Python related reason for this that I am not aware of?
In that case I also move my question here for which I didn’t find an answer in lesson 3:
This is more or less related to what we discussed about the curse of dimensionality earlier. Do we really want to merge this meta data to the rest of the training/test sets from the start?
I’m not sure about what I’m going to say but in the RL example @jeremy showed I think RF just stopped splitting its leafs at some point (based on the default hyperparameter max_depth I think) but these splits included data that were not really predictive. By removing them we allowed our trees to find the most relevant informations sooner and then ended up with trees of the same depth which splits were more “relevant”.
I think we could achieve the same level of “accuracy” with not removing the data but instead increasing the max_depth of the trees so they would split to something as relevant as if they directly started with the most important features.
Don’t hesitate to correct me on these statements, they are very speculative and can be completely wrong!
All I do here at this point is also only speculation I think you are right - with infinite number of splits and compute this wouldn’t matter, but as we only have log2(n) of splits available, then for the 20k rows we use that gives us only 14 splits! Crazy when you look at the actual numbers involving logs / exps  If we only have 14 splits, we want to use them as best as we can!
If we only have 14 splits, we want to use them as best as we can!
I am also thinking that that removal of data would not be necessary if we could have an arbitrarily large number of trees to fit. Then the noise would just cancel out I guess (assuming it was not super weirdly distributed?!). But since we can only have some probably small percentage of trees out of all the possibilities, we once again want to look at the relevant data - so we use what we learned earlier to limit the amount of garbage our model eats and feed it only the good stuff.
Only speculation so please take it with a grain of salt!
That sounds right to me.
I addressed this in detail in today’s class - check for a new video tomorrow
Also, pandas normally returns a view into the original data, rather than actually changing the data. This can be slow and memory intensive.
Yes exactly. Check out the proximity matrix for a really cool interpretation of this: https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm#prox
Mainly so that our feature importance plots are easier to interpret. Otherwise the importance measures can be split over multiple related features. Also, lots of highly related variables can mean that they are over-represented in the random sets of features we pick at each level.
There’s a horrible horrible python ‘feature’ that uses the exact same dict or list object if you put a dict or list as a default parameter. It leads to incredibly confusing bugs. So never put any kind of object as a default param!
Merging at the start, using pandas, is normally the best approach. Although this particular competition seems a little different - it’s essentially a collaborative filtering problem. So for my initial analysis I haven’t merged any tables!
Just added lesson 5 video to the top post.
If I am reading this right, having correlated columns can lead to our trees repeatedly choosing to split on what those columns represent (even with the param for showing it a subset of columns to chose from) and we might not get a chance to explore other, potentially useful splits?
Would this be an argument for additional preprocessing - doing PCA or something like that?
Slightly, yes, but really it’s the interpretation issue that’s important.
No, that totally kills interpretability, and also using a linear preprocessing approach can destroy the signal that a nonlinear model like RF can find.
Instead, simply change max_features to a higher number