I want to implement an image classifier in pure Tensorflow to understand better what is going on under the hood. And since I have a significantly easier access to a 24-core (2 socket) machine, then to a AWS p-something instance I decided to try out tensorflow on CPU-based machine. I compiled it with AVX instructions, but without MKL and without special memory allocator.
What I learned is that training performance of my model is significantly lower than I would expect. Comparing it to running the same model on p2.xlarge instance, the CPU machine is 6 times slower. And the reason, as I see it, is although I ask to use all the 24 cores, the actual system utilization is around 5-6.
In htop the utilization looks to change in waves. At some point all the cores are occupied, but this hold for relatively short period of time. And in the end of epoch only one core is occupied. On the scale utilization has a saw-like pattern.
I have couple of ideas how I can reduce the effect of low utilization. For example I can start using MKL, to speedup the serial part of the code. Or I can add data augmentation (as I intend in the future) to give more work for the stalling cores.
But what I would like to learn in this post is how to design an architecture, which produces less load imbalance. And is there a way to reduce serial part of the code by changing model architecture?
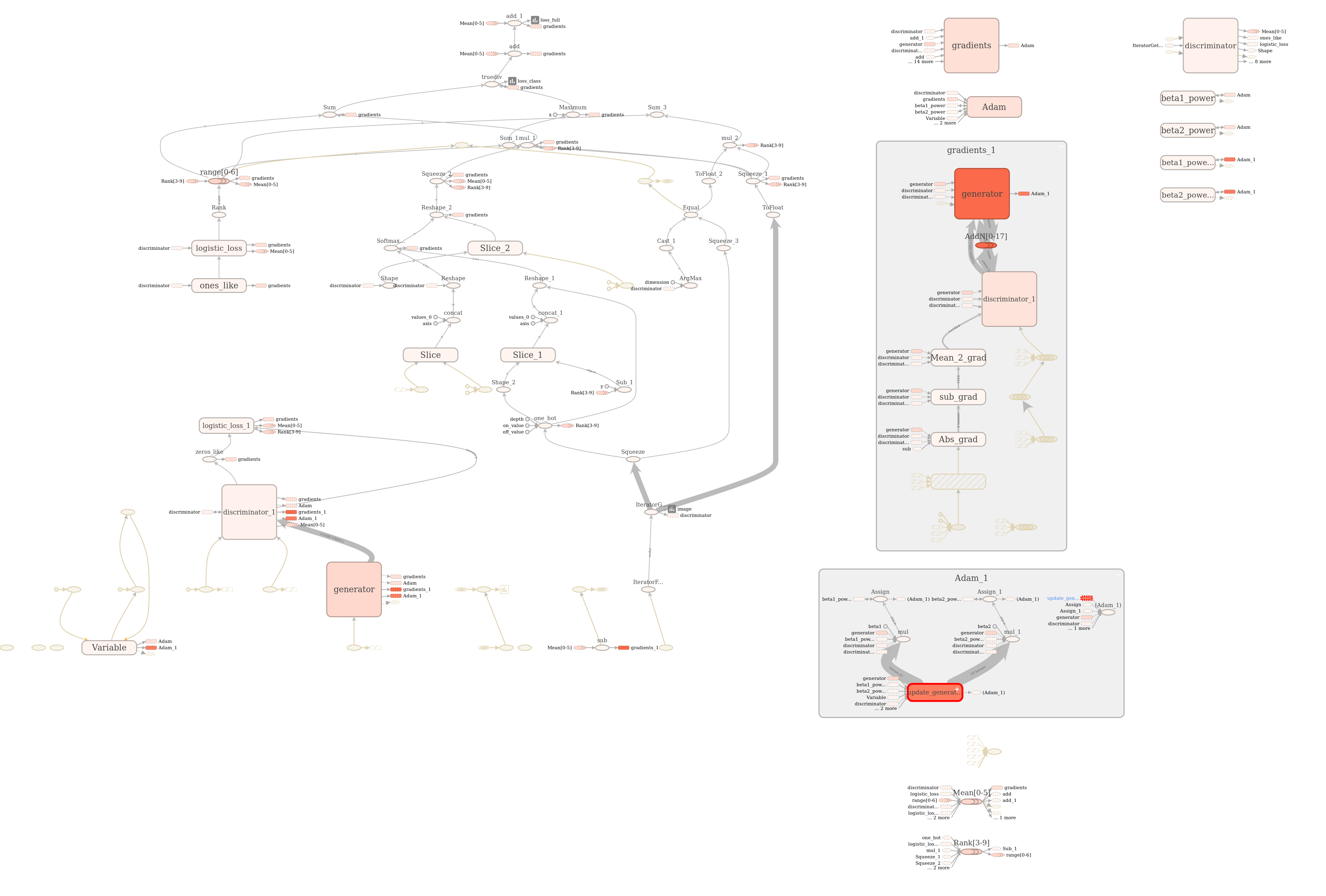
Now I will try to give more detail about my model. I use DCGAN with semi supervised learning is in “Improved Techniques for Training GANs”. I changed the exact implementation of both discriminator and generator, because my dataset consists of 300x400 pixel images. And in tensorboard graph it seems that the most time is dedicated to updating gradients in the generator (see picture)
I wanted to circle back on your post although I realize I am horribly late.
Recently, I have been in your shoes in attempting to reduce training time but I got mixed response from the forums (reddit/discourse etc) when I queried about the same in Fall’17 although I must admit that I did a bad job at constructing a good post. I did realize some of my assumptions and presumptions on reading your post may turn out to be wrong. So, I am not going to hesitate in posting a bunch of follow-up questions, which should hopefully give me more clarity on the topic. But before delving into those – do you mind sharing a simple high-level block diagram of your system to demonstrate load imbalance?
I have assumed that the deep learning AMI was a core part of your setup. Do you happen to use something like dockerfile to curate the sequence of dependencies (such as installing and not installing MKL)?
If you happened to use AWS p-something, did you happen to just leverage 1 GPU for training? Since you mentioned tensorflow, how did you monitor GPU usage during train time? Did you use flags or write simple APIs to limit the GPU usage. In other words, how did you intend to capture and monitor the underlying relation between train time and system utilization?
Why do you think the actual system util should be more than 5-6? Are you referring to some benchmarks? You mentioned the change in waves? Once again, how you interested in capturing the underlying relationship between the flow of tensors, epoch and core occupancy?
I am sorry if these seem to be a lot of questions – but I have been studying distributed tensorflow during the break and I am forced to think of the engineering aspects of the problem. Really looking forward to learning more about what you did!
sorry for slow response. I’m not using AMI, instead I’m building my image in a Singularity container, if it is any important.
I do not use GPU, I use CPU, as it says in the topic. I was monitoring CPU load in htop. I did not use any options to limit system utilization. I just saw that system utilization is lower than it could be and deduced, that I can get faster, if I increase system utilization.
I than that system util should be more than 5 or 6, because I have 24 cores, hence the maximum utilization is 24.
Regarding change in waves, I mean change in utilization which I observe in htop. It is not uniform 5-6, it is rather periodically changing from 18 to 1. The period is about epoch time, but I’m not sure if it is aligned exactly, because htop update granularity was too coarse for me.