I was having some troubles understanding the interactions between backend variables and the BFGS optimizer and reading the code wasn’t helping. I decided to code something from scratch to get my ideas straight unfortunately I have not managed to get my code working so I am asking for your help.
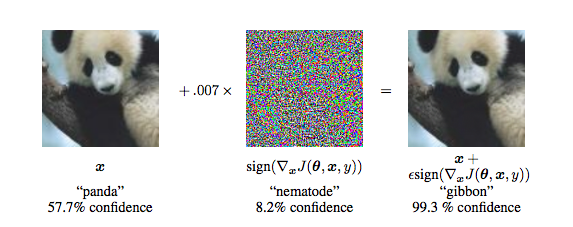
I tried to implement the ‘fast gradient sign method’ from this paper Explaining and Harnessing Adversarial Examples. The goal of this algorithm is to make changes to image imperceptible to the naked in order to fool the classifier. From what I understand, the algorithm is pretty simple:
take a image I and classify it using the neural network
compute the cross entropy loss with the wrong class
take the gradient of this loss according to the pixels of I
compute the sign of the gradient value for each pixel
multiply this gradient sign matrix by a very small number, this is our pertubation P
I manage to do all the steps but the model still does not make any mistake. There are a few things that I didn’t manage to figure out:
The documentation of keras.metrics.categorical_crossentropy state that the first argument should be the ground truth and the second one the predictions but If I call it this way, all my gradients are 0.
I have to take big values of epsilon otherwise nothing changes, I think this might have to do with the preprocessing step.
When I try to plt.imshow my modified picture, it is in negative, I have to call plt.imshow(256 - modified_array[0]).
My final goal was to build a transformation network to create adversarial samples really quickly (even if the method described earlier is fast).
Did you check Cleverhens "A library for benchmarking vulnerability to adversarial examples " repository on github? https://github.com/openai/cleverhans
I worked a bit more on my code and it seems that I had nearly everything right the first time. The main problem was that I was taking gradients relative to an arbitrary class the first time to compute the perturbation. It seems to work a lot better when I take a class that’s somewhat reasonable.
Here is the example I compute in the notebook:
Source image:
Classified as Labrador retriever 0.81% or Golden retriever 8%
Perturbated image:
Classified as wire-haired fox terrier 33% and tennis ball (!!) 19%.
This is really scary as the algorithms used on self-driving can be fooled as easily as this.
The method introduced in this paper is not targeted. So, you compute loss with true class not target/wrong class. Subsequent work also extended FGSM to targeted attacks but they require slight modification.
Yes, the perturbation can be computed in a targeted way. Most of the attack algorithms were covered pretty extensively in the recent Kaggle NIPS competition on targeted adversarial samples.
There is a lot a recent paper that explores adversarial samples designed to fool both human and machine learning systems. Below is their main example which I find quite shocking:
If anyone would like to know more about this subject I wrote a blog post on medium on it.
Thanks @rodgzilla. I also wrote an extensive tutorial on generating adversarial examples using PyTorch. It walks you through 4 different methods including the targeted ones. I wrote this more than a year ago and a lot has changed since. Generating Adversarial Examples


 Thanks for posting the notebook, I want to understand how this works.
Thanks for posting the notebook, I want to understand how this works.