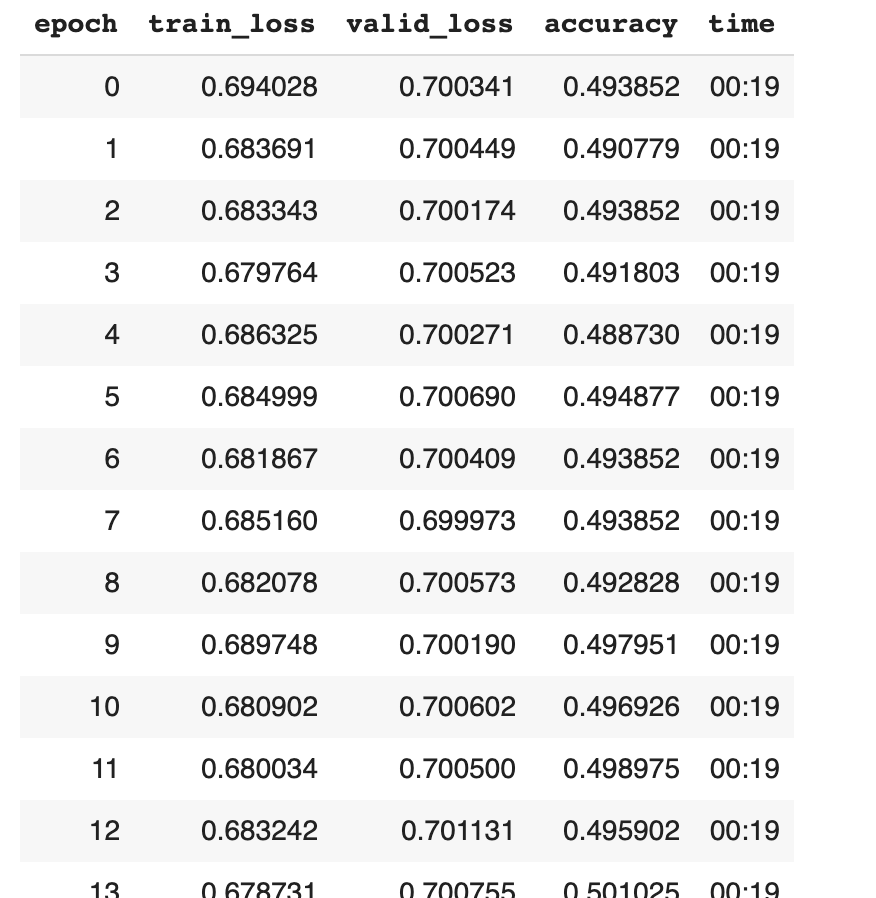
Hi, I use the resnet to classify images. But I get the a question that the accuracy is always around 0.5. I use the resnet50 and the dataset are 2 classes(0 and 1). I have tried the loss_func = LabelSmoothingCrossEntropy, but it did not work. And I have used the lr_find. Do anyone face the same question and find some solutions?


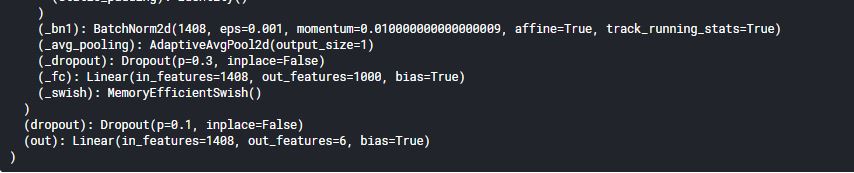
What does bias=True mean in last layer of efficient net.
Belwo is picture for more clarity.
And can we give out_features more than our classes in classification task.
Suppose I have 4 types of flowers in dataset. Can I use out_features=6 in efficient net.
If yes what are its pros or cons.
A picture of efficientNetB2.
thanks for the specifics
How can I increase the accuracy of perceptron model? I already done data normalisation by which i got a good result! My model jumped from 0.75 to 0.79. I want to increase it more till its possible. Shall I get some tips and techniques to do so?
MLP and CNN:
Recently I trained CNNs for image classification, and I have an idea about CNNs.
I’ve read the book which said that CNNs are trained by transforming to
MLPs with shared weights.
However, if we can train a good CNN, say ‘N’, by transforming it to M_N,
then we can also train an MLP ‘M’ that performs as good as ‘N’.
At least ‘M’ is the same as ‘M_N’.
We can even train ‘M’ to be better than ‘M_N’ since ‘N_M’ is restricted to share weights, while ‘M’ can be in any form.
What is the main reason that CNN can obtain good results on image classification while MLP can not?
Sorry for posting this question here, but I already looked on Google and couldn’t find an answer:
How do I post a new thread? I don’t see a “New” button when I browse this forum:
I am overwhelmed by your post with such a nice topic. Usually I visit your blogs and get updated through the information you include but today’s blog would be the most appreciable. Well done!
click here to learn data science course and applications of Artificial Intelligence
Hey Everyone,
I was doing transfer learning and I trained my model on MIDOG 2021 dataset, and I want to use that trained model to predict my own slides.
But the catch is I have .scn files as input images whereas the input data pipeline takes images in .tiff format.
The data used in training was in MS COCO format, here is the link for the dataset:
https://imig.science/midog2021/download-dataset/
Now how can I upload the .scn image as input for the model to do inference upon?
train_scanner = "aperio" #["Hamamatsu XR", "Hamamatsu S360", "Aperio CS"]
val_scanner = "aperio" #["Hamamatsu XR", "Hamamatsu S360", "Aperio CS"]
patch_size = 256
res_level = 0
train_annos = df[df["scanner"].isin(train_scanner.split(","))]
train_container = create_wsi_container(train_annos)
val_annos = df[df["scanner"].isin(val_scanner.split(","))]
valid_container = create_wsi_container(val_annos)
train_samples_per_scanner = 40
val_samples_per_scanner = 10
train_images = list(np.random.choice(train_container, train_samples_per_scanner))
valid_images = list(np.random.choice(valid_container, val_samples_per_scanner))
batch_size = 20
do_flip = True
flip_vert = True
max_rotate = 90
max_zoom = 1.1
max_lighting = 0.2
max_warp = 0.2
p_affine = 0.75
p_lighting = 0.75
tfms = get_transforms(do_flip=do_flip,
flip_vert=flip_vert,
max_rotate=max_rotate,
max_zoom=max_zoom,
max_lighting=max_lighting,
max_warp=max_warp,
p_affine=p_affine,
p_lighting=p_lighting)
train, valid = ObjectItemListSlide(train_images) ,ObjectItemListSlide(valid_images)
item_list = ItemLists(".", train, valid)
lls = item_list.label_from_func(lambda x: x.y, label_cls=SlideObjectCategoryList)
lls = lls.transform(tfms, tfm_y=True, size=patch_size)
data = lls.databunch(bs=batch_size, collate_fn=bb_pad_collate,num_workers=0).normalize()
print(data)
ImageDataBunch;
Train: SlideLabelList (40 items)
x: ObjectItemListSlide
Image (3, 256, 256),Image (3, 256, 256),Image (3, 256, 256),Image (3, 256, 256),Image (3, 256, 256)
y: SlideObjectCategoryList
ImageBBox (256, 256),ImageBBox (256, 256),ImageBBox (256, 256),ImageBBox (256, 256),ImageBBox (256, 256)
Path: .;
Valid: SlideLabelList (10 items)
x: ObjectItemListSlide
Image (3, 256, 256),Image (3, 256, 256),Image (3, 256, 256),Image (3, 256, 256),Image (3, 256, 256)
y: SlideObjectCategoryList
ImageBBox (256, 256),ImageBBox (256, 256),ImageBBox (256, 256),ImageBBox (256, 256),ImageBBox (256, 256)
Path: .;
Test: None
scales = [2]
ratios=[1]
#The feature map sizes. [(64,64), (32,32) , (16,16), (8,8), (4,4)]
sizes=[(32,32)]
anchors = create_anchors(sizes=sizes, ratios=ratios, scales=scales)
fig,ax = plt.subplots(figsize=(15,15))
ax.imshow(image2np(data.valid_ds[0][0].data))
for i, bbox in enumerate(anchors[:len(scales)*len(ratios)*len(sizes)]):
bb = bbox.numpy()
x = (bb[0] + 1) * patch_size / 2
y = (bb[1] + 1) * patch_size / 2
w = bb[2] * patch_size / 2
h = bb[3] * patch_size / 2
rect = [x,y,w,h]
draw_rect(ax,rect)
I tried using the same code and it gives me black images which I know means that .scn images are not being loaded.

Please provide any suggestions or resources: notebooks, code snippets,etc which can help me fit this image data into my existing pipeline.
I have saved the statedict of my already trained model as follows:
torch.save(learn.model.state_dict(),'bs64_inference.pth')
And I’ll just do torch.load to load and run a model on the .scn image, is there a better way for me to load the learner(or model)?
Also, I have used fastai-object-detection library for training my model so all the methods that are supported are of FastAi 1.0.61, so please do mind this gap in versions.
The annotation file I have is in same format as of MIDOG 2021 challenge, i.e. in MS COCO format.
The directory structure is also same as of MS COCO:
->INPUT DIRECTORY:
*******:IMAGES
*********************:0.scn
*******:annotation0.json
Hello , I have a question, I need to update my dense layer weights values with once that i have calculated them separately but i’m not able to do that ?
Thanks in advance
Hi, I am looking for ideas on how to make Ramen AI better.
I built this tool to classify text using LLM AI without model training and without pre-labeling.
If you got some, I’d love to know. The tool is free.
Thanks for sharing this article. As checking to learn Deep learning topics projects etc. It will helpful for me. React JS Online Course