Will do.
And perhaps a silly question - why are we calling tensors x in first place? why not t or tens or tensor?
Will do.
And perhaps a silly question - why are we calling tensors x in first place? why not t or tens or tensor?
I think they are math symbols used in equations where DL is derived. Usually, in equations x is for vector, X is for matrix and x is for scalar used as independent variables in math formulas.
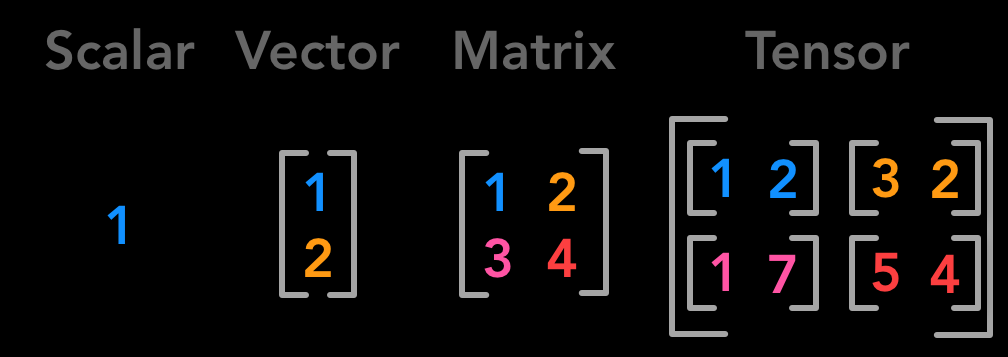
As jeremy mentioned I like the idea of being explicit about tensors as image , etc.
I like this image from link
Yes, I’m aware of the math. And that’s why asked the question - x as it used in math f(x), could mean any of the 4 types you presented in the image, and not just the tensor (which usually stands for 3+ dimensions in math), and even a scalar (with very small variations, such as an arrow above x, upcase, etc.). That’s why to me x doesn’t tell anything about the inner structure of the variable.
Moreover, here when we say tensor in the context of fastai, we mean a pytorch tensor variable. You could just as well have a multi-dimensional numpy structure, and mathematically it’s the same. So how in the code one could tell whether x is a pytorch var or a numpy var?
So how in the code one could tell whether x is a pytorch var or a numpy var?
I believe this is where duck-typing should come in (and I think this was agreed upon as something that should be done…right?):
def something(self, x: torch.Tensor, y : np.ndarray):
I mean that’s one way at least. I think that’s probably better than trying do comments (that quickly go out of sync with code) or a Hungarian notation thing (that gets messy/overloaded/confusing quickly).
This is definitely where Python gets on my nerves (coming from Java/C#).
Now of course there’s also the dimensionality of the tensors/ndarrays and how to interpret them. That’s not solved by duct-typing. Maybe ample comments are the best solution in this case… I certainly don’t like having to run code just to figure it out though. But that sort of thing is really hard to get a lot of people to do in practice (just like saying- “hey, run unit tests!”). In the case of unit tests- you can at least make the build fail and engineer away neglect. But comments…that’s another beast.
EDIT Personally…this is where my Java mind comes in and says “make wrapper objects” when you’re passing around things tensors and ndarrays, so that they have a type associated with them and perhaps provide basic assessors that inform how to interpret the tensors by just doing it in code (rather than relying on comments, for example). But I know that can be considered “over-engineering” because gasp- there’s more classes to deal with. But IMHO…code is -way- better than convention and comments in communicating what’s -actually- going on.
EDIT 2 To expand on the above idea a bit: Tensors/ndarrays are really low level, and it seems like they shouldn’t be the primary thing you’re having to think about when dealing with functions that talk to each other on high level things such as “predict”,“display image” etc. It’s a lot of unnecessary mental clutter, imho.
heh - I just suggested t in your PR  I kinda hate using
I kinda hate using x
We’ll be adding type annotations to all params.
Ah! Fantastic!
I strongly agree with @jsa169
Abbreviations make things a lot harder to read. I’ve been coding professionally for about five years now and I always see beginners make the mistake of being too cryptic with their code. The purpose of using a programming language is to make it easier to talk to the computer, not harder.
I just started watching Part 1’s lessons recently and the hardest things for me so far when it comes to code have been the massive amounts of global imports and the abbreviations.
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
When it comes to imports, it’s better to import the library then call its functions Library.some_function() instead of a cryptic some_function(). Knowing what library is being called makes it a lot easier to understand intent, and helps when you want to look up documentation when necessary.
Jason’s example is perfect (copying pasting for readability).
def seq2seq_loss(input, target):
sl,bs = target.size()
sl_in,bs_in,nc = input.size()
..... (truncated)
def sequence2sequence_loss(input, target):
target_sequence_length, target_batch_size = target.size()
input_sequence_length, input_batch_size, num_unique_tokens = input.size()
....(truncated)
The second example is readable, the first isn’t.
Hope this feedback helps.
Matan
Please don’t re-cover things that have been extensively discussed on the forum, in the style guide, and in the lessons.
I have to apologize for starting this. You’ve definitely covered this and I think I’m one of those programmers that you’re referring to here in the quote below. I’m going to try to make a conscious effort to not let knee-jerk reactions on short names that I’ve developed over the years get in the way of understanding the benefits. (I’ll try!)  Anyway- it’s definitely a new approach to me and I know it’s going to be for many others.
Anyway- it’s definitely a new approach to me and I know it’s going to be for many others.
Everyone has strong opinions about coding style, except perhaps some very experienced coders, who have used many languages, who realize there’s lots of different perfectly acceptable approaches. The python community has particularly strongly held views, on the whole. I suspect this is related to Python being a language targeted at beginners, and therefore there are a lot of users with limited experience in other languages; however this is just a guess.
I think it’ll be helpful to link to what you’re referring to- yes, we’re beating a dead horse.
Forum discussion
Style guide
Thanks, good reads.
Makes more sense now why you would want more condensed code for math related stuff, especially when contributing code as opposed to just using the library.
@stas FYI @rachel has just started adding prose to the first notebook. To avoid annoying problems with merging, you probably want to know about this:
Yes, nbdime is great. Thank you.
Perhaps @rachel could notify me when her changes have been merged - so that we don’t step on each other’s toes, and I will resume then.
(I’ve been migrating to kubuntu 18.04 so I’ve been away)
Actually the toe-stepping may be a problem, since @313V has started working on adding prose to the other notebooks now too. So I’ve suggested to him that maybe it’s easier for him to do the renaming as he goes. If you’ve already made some changes @stas it might be a good idea to push them.
No, not yet. I was just finishing the setup of the new 18.04 env.
Actually the toe-stepping may be a problem, since @313V has started working on adding prose to the other notebooks now too.
ok, then I will occupy myself with other things for now.
and there are 2 outstanding questions waiting for your attention @jeremy (naming-wise):
Thanks
Python modules use _, so let’s do that in nbs too.
I don’t think so - because this pattern is nearly always in for xb,yb in dl, where we don’t want long names. I know in the notebooks we have this pattern separated out, but I’d like to keep it consistent with how people will generally see it in the code.
@313V please let me know if I can help you with adding prose to the notebooks. I have been following the discussions closely and have free time available.
help would be great, technical writing isn’t necessarily my strength anyway so at minimum someone to help review and edit would be awesome and i’m sure you could add a lot more than that.
What time zone are you in? Are you on any kind of video chat like skype/gchat/facetime etc? It would be cool to chat face to face and form a plan of attack.
Sorry, this got miscommunicated, quoting again:
loss_fn(model(x_valid[0:bs]), y_valid[0:bs])
xb, yb = next(iter(valid_dl))
Should x_valid and y_valid be valid_x and valid_y? I quoted the second line because of valid_dl
More examples of inconsistencies from the current codebase:
data = DataBunch (train_ds, valid_ds,
data = DataBunch.from_arrays(x_train,y_train,x_valid,y_valid, x_tfms=mnist2image)\n",
should these be: train_x,train_y,valid_x,valid_y? It’d now look:
data = DataBunch (train_ds, valid_ds,
data = DataBunch.from_arrays(train_x,train_y,valid_x,valid_y, x_tfms=mnist2image)\n",
except x_tfms is now a mismatch with this group. But it’s _tfms everywhere in the current code so it’s probably good.
Good, so could one of you with commit access do the filename renaming - it’d complicate things to do this via PR, if changes happen in the files meanwhile.
and also I mentioned keeping consistent casing would be awesome too - it seems that all-low-case are the majority of files so far, so perhaps renaming files to lowercase would be a sensible choice.
if you have https://stackoverflow.org/wiki/Rename.pl it’s 2 secs:
rename.pl 's|-|_|g' *ipynb
rename.pl '$_=lc $_' *ipynb
Thank you.